W sieci krąży całe mnóstwo przykładowych kodów źródłowych, napisanych mniej lub bardziej elegancko i poprawnie (to, że program działa nie implikuje, że jest poprawny :) - ten ani nie działa - daje błędne wyniki, ani nie jest poprawny, ani nie jest elegancki). Spotkałem dziś paczkę zawierającą kilka prostych programów obliczających pola figur. Paczka ma być “Przydatna dla ludzi, którzy nie mają pojęcia o programowaniu”, czyli, jak rozumiem ma stanowić pewnego rodzaju wzór z którego można się czegoś dobrego nauczyć i co warto naśladować. Dobre przykłady są fundamentem nauki programowania, ale nie każdy przykład jest dobry.
#include <iostream>
#include <conio.h>
using namespace std;
int main()
{
int r;
float pi=3.14;
cout << "Pole kola\n";
cout << "Podaj dlugosc promienia: ";
cin >> r;
cout << "\n";
int p_kola(pi * (r * r));
cout << "Pole wynosi: " << p_kola;
getch();
return 0;
}
Plik nagłówkowy conio.h nie jest częścią standardu języka C ani C++ ani POSIX. Wywodzi się on jeszcze z dawnych kompilatorów działających w systemie DOS (np. ja osobiście kojarzę go z kompilatorów Borland Turbo C++). Używając tej biblioteki tworzymy nieprzenaszalny kod. Bez dodatkowych czynności nie będzie kompilował się na przykład w systemach uniksopodobnych. Nie jest to dobra praktyka. Dobrze byłoby ograniczyć się do używania jedynie bibliotek wchodzących w standard, co w przyszłości może zaowocować łatwiejszą pielęgnacją i utrzymaniem kodu. W tym przypadku to oczywiście nic poważnego, ale warto wyrabiać sobie dobre nawyki.
Stałe powinno się opatrywać dodatkowym słowem kluczowym const. To również niby nic wielkiego, ale stosowanie const poprawia właściwość “samo-komentowania się” kodu. Gdy patrzymy na duży objętościowo kod, wyłapanie słów const pomaga w “uchwyceniu” koncepcji działania programu.
Linijka 14 jest kwintesencją całego przykładu. Wyraźnie widać, że autor chciał się pochwalić obiektowością. Programiści często lubią się chwalić różnymi wysublimowanymi konstrukcjami. Tylko, że na dłuższą metę to również nie jest dobra praktyka. Kod należy pisać w sposób możliwie najprostszy, bez żadnych własnych udziwnień, cały czas obierając sobie za cel to, aby inny programista był w stanie szybko zrozumieć naszą wizję i kontynuować tworzenie kodu. Język C++ umożliwia traktowanie typów prostych jak klas i wykonywanie rzutowania podczas tworzenia obiektu poprzez podawanie wyrażenia w konstruktorze. Tyle, że jest to straszliwe udziwnienie, nie wnoszące żadnej wartości dydaktycznej a jedynie mogące namieszać osobie uczącej się programowania. Nie wspominam już tutaj o tym, że pole nie koniecznie musi być liczbą całkowita, o czym autor chyba zapomniał w przypływie zachwytu nad właśnie zastosowanym konstruktorem typu prostego int.
Ten przykład skłania do szerszej refleksji na temat jakości merytorycznej dostępnych w Internecie materiałów. Często słyszałem od ludzi nauki, że Internet jako źródło wiedzy jest swoistym śmietnikiem. Niestety wraz z upowszechnianiem się dostępu do Internetu wzrasta ilość treści bezwartościowych. Mógłbym nawet zaryzykować twierdzenie, że w pewnym sensie czasy gdy mało kto miał dostęp do Internetu miały swoje zalety. Obecnie wszędzie gdzie tylko można postuluje się najlepiej darmowy dostęp do Internetu i najlepiej dla wszystkich. Nie twierdzę, że w Internecie nie ma treści wartościowych. Oczywiście, że są. Wraz z rozwojem Internetu ogromnie dużo ich przybyło. To świetnie. Tylko, że przybyło również ogromnie dużo śmieci, a surfowanie po śmietnisku przestaje być przyjemne.
Co prawda z tego przykładu skorzystają jedynie studenci PW, ale sam mechanizm warto znać, ponieważ może się przydać. Rzecz dotyczy możliwości uruchomienia programu okienkowego na zdalnym unixowym serwerze na którym mamy konto. Wydając pod linuxem polecenie:
ssh -l nazwa_uzytkownika -X adres_serwera
uzyskujemy dostęp do konsoli na naszym koncie. Przełącznik -X dodatkowo daje możliwość korzystania nie tylko z aplikacji konsolowych, ale również z okienkowych.
Praktycznym przykładem na zastosowanie tego polecenia jest uzyskanie dostępu do zasobów czytelni ibuk.pl z dowolnego miejsca. Studenci PW (zapewne również innych uczelni) mają zapewniony darmowy dostęp do książek w tym serwisie. Warunkiem jest jednak otwarcie serwisu z sieci należącej do uczelni. Jeżeli ktoś chce uzyskać dostęp z domu (1 na poniższym rysunku) może dzięki temu otworzyć sobie sesję na serwerze uczelnianym (2) i uruchomić na nim przeglądarkę, która będzie pobierała książkę z serwera ibuk.pl (3) - widok okienka z przeglądarką jest przesyłany do domowego komputera (1) przez bezpieczne połączenie ssh.
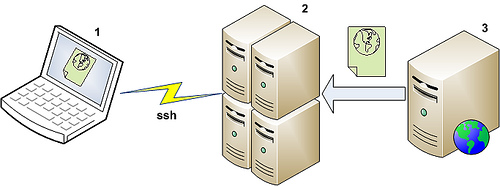
Dostęp do książek jest ograniczony do tematyki technicznej, co jest zrozumiałe jeżeli zorganizowała to PW dla swoich studentów. Poniżej zrzut ekranu z otwartą książką:
Wszystkie współczesne routery domowe posiadają opcję konfiguracji przez UPnP. Wbrew pozorom nie ma to nic wspólnego z technologią Plug and Play która służy do autokonfiguracji podłączanych do komputera urządzeń (ktoś jeszcze pamięta ręczne wpisywanie numerów przerwań i kanału DMA? ;) ). Universal Plug and Play to zbiór protokołów umożliwiających wysłanie do routera polecenia o tymczasowej zmianie w konfiguracji NAT. Rozwiązanie to jest stosowane m. in. w kliencie Bittorrent’a Azureus (nie mogę przyzwyczaić się do nowej nazwy - Vuze) oraz kliencie sieci eDonkey - eMule. Zaletą tego rozwiązania jest wygoda - program sam konfiguruje sobie tymczasowe (tj. znikające po restarcie urządzenia) przekierowanie portów i bez problemu przyjmuje połączenia przychodzące. Często można spotkać nie do końca uzasadnione “porady”, że stosowanie UPnP jest niebezpieczne. Owszem, włączając tę opcję w routerze musimy być świadomi, że pomimo ręcznej konfiguracji NAT uruchomiony na komputerze w sieci lokalnej program może stworzyć sobie nową własną regułę. Jednak byłbym daleki od twierdzenia, że opcja sama w sobie jest potencjalnie niebezpieczna. Przy stosowaniu podstawowych zasad bezpieczeństwa (aktualizacje oprogramowania i systemu operacyjnego, program anty-wirusowy i anty-spyware, firewall) w połączeniu ze zdrowym rozsądkiem, korzystanie z UPnP przynosi więcej korzyści niż wad.
Znalazłem na CodeProject program, który umożliwia wyświetlenie oraz edycję wspomnianej tymczasowej konfiguracji NAT. Jest to UPnP Port Forward Utility.
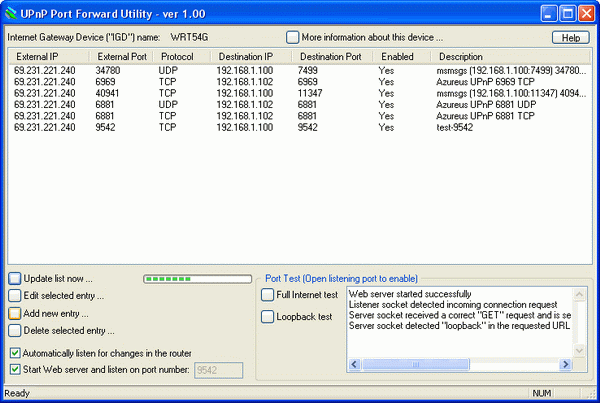
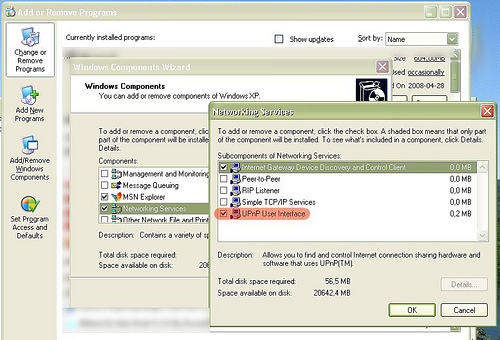
Może on być przydatnym narzędziem gdy zachodzi potrzeba szybkiego (bez konieczności logowania się do routera) wprowadzenia zmian w przekierowaniu portów, albo po prostu zweryfikowania co też poustawiały sobie uruchomione programy. Z moich eksperymentów zauważyłem, że do poprawnego działania programu konieczne jest zainstalowanie interfejsu UPnP ze składników Windows (w miejscach sieciowych pojawia się wówczas ikonka routera).
Zastanawiałem się kiedyś co się stanie gdy podłączy się komputer do sieci z wielu “źródeł”. Co prawda rzadko się zdarza, aby w komputerze desktopowym było wiele kart sieciowych, ale już w laptopach zazwyczaj są 2 urządzenia sieciowe - zwykła karta sieciowa Ethernet i karta bezprzewodowa. Nasuwa się pytanie czy można uruchomić oba połączenia jednocześnie. Okazuje się, że można - system wybierze “lepsze” z nich i przez nie będą nawiązywane połączenia.
Szczegółowe wyjaśnienie można wydobyć z tablicy routingu. Jest to tabela zawierająca informacje o tym gdzie i którędy przekazać informacje kierowane pod dany adres sieciowy. Podczas przesyłania pakietów danych pod konkretny adres analizowane są po kolei wpisy z tablicy routingu i na tej podstawie podejmowana jest decyzja o trasie jaką ten pakiet wędruje. Jeżeli żaden z wpisów tablicy “nie pasuje”, to pakiet kierowany jest do bramy domyślnej czyli w przypadku sieci lokalnych zazwyczaj do routera który podłączony jest do Internetu. Tablicę routingu w systemie Windows (w sumie to nie tylko) można wyświetlić poleceniem route print
Poniżej przykładowo ekran z moją tablicą:
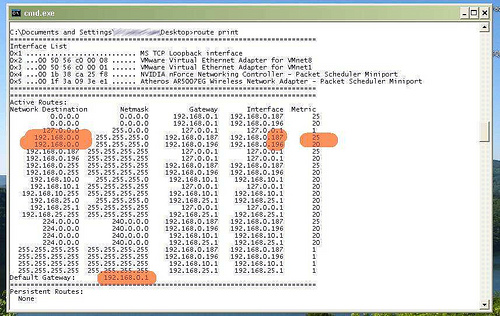
Z tablicy wynika, że połączenia “do świata” kierowane są do bramy domyślnej - mojego routera - na 192.168.0.1. Wynika również, że połączenia do podsieci 192.168.0.0 (czyli w konsekwencji przez bramę domyślną do świata) realizowane są przez 2 interfejsy: 192.168.0.187 i 192.168.0.196. Ten drugi to Ethernet. On właśnie ma mniejszą metrykę, czyli szacunkowy koszt połączenia. System wybiera połączenia z mniejszą metryką. Usuwając ręcznie jeden z wpisów poleceniem route można by upewnić się, że mimo fizycznego podłączenia przez 2 interfejsy używany jest tylko jeden. Tablica routingu jest aktualizowana automatycznie po ustanowieniu połączenia na dowolnym interfejsie sieciowym.
Praktyczny wniosek jest taki, że jeżeli mamy komputer podłączony do sieci bezprzewodowo i dodatkowo podłączymy go również do tej sieci kablem, to transmisja będzie się odbywała właśnie po kablu pomimo aktywnego połączenia bezprzewodowego.
W przeglądarce Firefox od wersji 3 funkcjonalność zakładek i historii została zaimplementowana jako relacyjna baza danych SQLite. Wiąże się to ze znacznym zwiększeniem możliwości przeszukiwania zgromadzonych w ten sposób informacji, choć niestety z elastyczności tej nie można w pełni korzystać bezpośrednio z przeglądarki. Z Internetu korzystam w dość intensywny sposób, w przeglądarce mam ponad 2000 zakładek i codziennie zdarza się dodawać nowe. Chociaż staram się to jakoś zorganizować według folderów i etykiet, jednak do pełni szczęścia potrzebowałem 2 informacji:
Ponieważ jest to baza danych, od razu przychodzi na myśl potencjalna możliwość zadawania zapytań w języku SQL. Poniżej opisuję narzędzia którymi można to zrobić, ich sposób użycia oraz kod przykładowych zapytań SQL.
Znaleziony i używany przeze mnie program do otwierania bazy danych SQLite to SQLite Browser. Nie wymaga on instalacji, bezpośredni link spod którego można go pobrać jest tutaj.
Dodatkowe informacje i narzędzia (które jednak nie są konieczne do wykonania tej “sztuczki”), w tym również fizyczny schemat bazy danych użytej w Firefoksie znajduje się na http://www.firefoxforensics.com/.
Pierwszą czynnością jaką należy wykonać jest skopiowanie (dla bezpieczeństwa) pliku bazy danych w inne miejsce spod, którego będzie on otwierany w SQLite Browser. Może być konieczne włączenie widoku ukrytych plików w opcjach folderów Windows. Plik nazywa się “places.sqlite” i znajduje się
W systemie Windows XP:
C:\Documents and Settings\<nazwa użytkownika>\Application Data\Mozilla\Firefox\Profiles\<ciąg znaków i cyfr>\
W systemie Windows Vista:
C:\Users\<nazwa użytkownika>\AppData\Roaming\Mozilla\Firefox\Profiles\<ciąg znaków i cyfr>\
Po uruchomieniu SQLite Browser otwieramy skopiowany plik “places.sqlite” i przechodzimy do zakładki Execute SQL. W pierwszym okienku wklejamy kod zapytania SQL a w kolejnym okienku baza danych podaje wynik. Poniżej kilka przykładowych zapytań.
1. Folder zawierający daną zakładkę. Nazwę szukanej zakładki wpisujemy pomiędzy znaki %, tutaj jest to “codeflux”.
SELECT title FROM moz_bookmarks WHERE id = (SELECT moz_bookmarks.parent
from
moz_bookmarks, moz_places
where moz_places.url like '%codeflux%'
AND
moz_bookmarks.fk = moz_places.id
AND
moz_places.visit_count > 0)
2. Zakładki dodane w ciągu ostatnich x dni. Tutaj sprawa może być trochę bardziej skomplikowana, jeśli wśród naszych zakładek znajdują się kanały RSS. Z punktu widzenia bazy danych są one nieodróżnialne od zwykłych zakładek, a ponieważ kanały RSS aktualizują się bardzo często może się okazać że większość wyniku tego zapytania będą stanowić jakieś pozycje np. aktualności z kanału RSS. Niemniej jednak ten sposób korzystania z RSS jest mało efektywny (polecam Google Reader) i raczej rzadko używany, więc nie powinno to stanowić problemu. W poniższym zapytaniu liczba dni to 4.
select datetime( (dateAdded/1000000), 'unixepoch' ) , moz_bookmarks.title, moz_places.url, moz_bookmarks.parent
from
moz_bookmarks, moz_places
where ( strftime('%s', 'now') - strftime('%s', datetime( (dateAdded/1000000),'unixepoch')) < 4*86400) AND
moz_bookmarks.fk = moz_places.id
AND
moz_places.visit_count > 0
3. 20 najczęściej odwiedzanych stron.
SELECT *
FROM moz_places
ORDER by visit_count DESC
LIMIT 20
4. Liczba unikatowych stron internetowych. Z moich obserwacji wynika, że chodzi o liczbę różnych stron w tym sensie, że wszystkie odwiedzane podstrony liczą się raz - tak jak strona główna. Przykładowo - wejście na stronę Onet.pl i przeglądanie działów prognoz pogody, wiadomości, sportu również będzie się liczyło raz - ponieważ wszystko to jest “w obrębie” strony Onet.pl. Liczba jest tylko przybliżona, bo mogą wliczyć się pobierane pliki oraz niektóre długie i nietypowe adresy mogą policzyć się kilka razy chociaż są podstronami. Z resztą widać to na liście tych stron - punkt 4.
SELECT COUNT(*) FROM ( SELECT count(moz_places.rev_host), url
FROM moz_places, moz_historyvisits
WHERE moz_places.id = moz_historyvisits.place_id
GROUP BY moz_places.rev_host
ORDER BY url ASC )
5. Jak wyżej, tylko lista tych stron
SELECT count(moz_places.rev_host), url
FROM moz_places, moz_historyvisits
WHERE moz_places.id = moz_historyvisits.place_id
GROUP BY moz_places.rev_host
ORDER BY url ASC
6. Lista wszystkich adresów internetowych przechowywanych w historii
SELECT url, datetime( (visit_date/1000000), 'unixepoch' )
FROM moz_places, moz_historyvisits
WHERE [moz_places.id](http://moz_places.id) = moz_historyvisits.place_id
ORDER by visit_date DESC
Kilka nieco innych zapytań znajduje się na wspominanej wyżej stronie Firefoxforensics. Zachęcam do różnych twórczych eksperymentów z formułowaniem zapytań - jeśli uda się napisać coś ciekawego zapraszam do komentarzy. Polecam raczej wzorowanie się na istniejących zapytaniach niż próbę zrozumienia struktury bazy danych - widać, że jest ona zdenormalizowana (zapewne aby zapewnić szybkość działania nowego paska adresu) i przez to dość niejasna. Co prawda pewnie na deweloperskich stronach Mozilli znajduje się dokumentacja, ale osobiście nie miałem ochoty w to wnikać. Bardzo dobrym (na początek) źródłem wiedzy o języku SQL jest dział na stronie W3Schools.
Wpis dotyczy sztuczki, która może przydać się użytkownikom wieloprocesorowych komputerów pracujących pod kontrolą systemu Windows (oczywiście jest to możliwe również w systemach uniksowych, ale nie zajmowałem się tym).
Planista jest częścią jądra systemu operacyjnego, która odpowiada za rozplanowanie w czasie przydziału wykonujących się programów do procesora. Nie zagłębiając się w szczegóły techniczne, warto wiedzieć że we współczesnych komputerach w ciągu jednej sekundy takie przełączenia pomiędzy jednym wykonywanym programem a kolejnym liczy się w setkach albo nawet tysiącach. W tej tematyce szczególnie polecam dwie bardzo dobre książki: Uresh Vahalia “Jądro systemu Unix” oraz Abraham Silberschatz “Podstawy Systemów Operacyjnych“
Również bez zagłębiania się w szczegóły techniczne, w miarę intuicyjne i oczywiste jest to, że jeżeli posiadamy komputer z wielordzeniowym procesorem to różne programy mogą wykonywać się równolegle. Jeżeli program obsługuje wielordzeniowy procesor (program jest wielowątkowy) to na takiej maszynie będzie wykonywał się tyle razy szybciej ile procesor ma rdzeni. Obserwując użycie procesora w komputerze z procesorem wielordzeniowym widać, że ten sam program może być wykonywany na wielu rdzeniach nawet jeśli nie jest wielowątkowy. Obciążenie rozkłada się wtedy równomiernie i sumaryczne obciążenie wszystkich rdzeni jest odwrotnie proporcjonalne do liczby rdzeni.
Pomysł z równomiernym rozkładaniem obciążenia z całą pewnością jest sensowny i nie mam zamiaru wnikać w techniczne powody dlaczego tak to zostało zrobione. Niemniej jednak zauważyłem, że zdarzają się sytuacje, gdy ta równomierność może być uciążliwa. W sytuacji, gdy wykonujemy jakąś intensywnie obliczeniowo aplikację typu kodowanie filmu, muzyki, zdjęć przez dłuższy czas i jednocześnie chcemy np. korzystać z przeglądarki internetowej to widać, że działa ona znacznie wolniej ponieważ “dzieli” procesor z “żarłoczną” aplikacją do kodowania. W takiej sytuacji warto zmusić system operacyjny, aby konkretna aplikacja wykonywała się tylko na konkretnym jednym rdzeniu procesora. Dzięki temu chociaż nasze kodowanie potrwa dłużej (ale zazwyczaj nie ma dla nas znaczenia czy jest to 10 czy 15 minut), ale znacznie polepszy się responsywność tej drugiej aplikacji na której chcemy działać cały czas - np. przeglądarki internetowej. Z obserwacji widzę, że działa ona mniej więcej tak sprawnie jakby w tle nie wykonywała się żadna intensywna operacja typu kodowanie. W systemie Windows takiego przydziału programu do rdzenia procesora dokonuje się np. przy użyciu darmowego narzędzia firmy Sysinternals (która jest obecnie częścią Microsoftu) - Proces Explorer’a. Klikamy prawym przyciskiem myszki na proces (proces - to wykonujący się program) i wybieramy opcję ‘Set affinity’. Moim zdaniem warto poeksperymentować z przydzielaniem procesów tylko do pojedynczych rdzeni - można uzyskać ciekawe zwiększenie responsywności systemu podczas wykonywania wielu różnych nietypowych programów.
PS1. Warto wiedzieć, że Sysinternals udostępnia wszystkie swoje narzędzia w postaci współdzielonego folderu przez protokół SMB pod adresem live.sysinternals.com - należy wpisać ten adres w polu ‘adres’ dowolnego okna eksploratora Windows lub w poleceniu Start/Uruchom.
PS2. Chcąc zautomatyzować uruchamianie programu tylko na konkretnym rdzeniu można użyć darmowego konsolowego narzędzia RunFirst, które uruchamia wskazany program zawsze na pierwszym rdzeniu procesora.