I have decided to publish new blog posts only in English. I have always been trying to provide information that can be useful for other people. Writing only in Polish language hinders me from reaching my target audience. Which can potentially be everywhere, not only in my country. In my experience I have already come across situations when I find something useful and cannot benefit from it, because it is written only in German or only in Italian. I would not like to make such mistakes. English language is the most appropriate tool for establishing connection with and reaching people worldwide. I also do believe my Polish readers will not suffer much  as knowledge of English in my country is not too bad.
as knowledge of English in my country is not too bad.
UPDATE – March 18, 2013. I have started new technical blog: blog.pjsen.eu. All new technical content will be published there in English. Here some minor, Polish-specific thoughts will be shared.
Oprogramowanie o otwartym kodzie źródłowym, jak by się mogło wydawać, budzi ogromny entuzjazm zarówno wśród programistów, jak i użytkowników. Programiści przykładowo mają możliwość korzystania z potencjału drzemiącego w ogólnodostępnym dla wszystkich kodzie źródłowym. W przypadku zaś darmowych narzędzi i bibliotek – w znaczący sposób zmniejszają one koszty wytwarzania oprogramowania. Jakby tego było mało, można liczyć na pomoc przyjaźnie nastawionej społeczności innych entuzjastów, która gotowa jest pomóc nawet w najcięższych przypadkach. Jak by się mogło wydawać, również użytkownicy oprogramowania o otwartym kodzie źródłowym powinni być wielce usatysfakcjonowani, ponieważ nie dość, że mają produkt za darmo, to jeszcze mają świadomość, iż został on stworzony przez prawdziwych specjalistów, pracujących nad rozwojem programu “z potrzeby serca”.
Niestety, jak to w życiu bywa, pozory mylą i powyższy obraz jest czysto teoretyczny. Nie będę omawiać wątpliwości dot. aspektów użytkowych oprogramowania open-source, ponieważ jest to temat na oddzielny post. Chciałbym skupić się na zagadnieniach istotnych z punktu widzenia programisty oraz podać konkretny przykład, który mnie osobiście zabolał.
W ostatnim czasie spotkałem się z opinią zawodowego programisty, iż korzystanie z rozwiązań open-source w poważnym komercyjnym projekcie może być ryzykowne, kosztowne, a nawet szkodliwe. Uzasadniając swoje zdanie, programista ten przedstawił kilka konkretnych zarzutów:
Nikt osobiście nie bierze odpowiedzialności za zagwarantowanie rozwoju, uaktualnień oraz wsparcia dla rozwiązań open-source. Podany został przykład sytuacji, gdy w pracach nad komercyjnym projektem szeroko wykorzystywano darmową bibliotekę. W pewnym momencie wydana została nowa wersja biblioteki, całkowicie niekompatybilna z poprzednią. Autor biblioteki całkowicie “odciął” się od starej wersji i zaprzestał jej utrzymywania. Zespół stanął przed dramatycznym wyborem: korzystać ze starej wersji narażając się na wszelkie kłopoty z tym związane, czy całkowicie przepisać projekt, tak by korzystał z nowej wersji. Wybrano to drugie rozwiązanie, co z punktu widzenia rozwoju stanowiło półroczny przestój.
Wsparcie społeczności również nie jest czymś, co może być w jakikolwiek sposób zagwarantowane. Czasami bywa też tak, że projekt “umiera” i nikt, z autorem włącznie, już się nim nie interesuje. Wtedy nawet nie wiadomo do kogo zwrócić się w przypadku problemów.
Otwarty kod źródłowy wcale nie oznacza szybszego reagowania na błędy. Znane są przypadki, gdy autorzy całkowicie ignorowali błędy znajdowane przez użytkowników. Programiści musieli poprawiać znaleziony przez nich samych błąd w bibliotece samodzielnie kompilując każdą kolejną jej wersję, tak aby nadawała się do użytku w ich projekcie. Skutkiem tego było to, iż zespół przeznaczony do prac nad projektem de facto pracował nad dwoma projektami: właściwym projektem + biblioteką, która była im potrzebna.
Dokumentacja w przypadku open-source to jest coś, co może istnieć, ale wcale nie musi.
Opublikowany przez autora kod źródłowy może być w postaci kompletnie nieutrzymywalnej. I na przykład może się wcale nie kompilować. Takie przypadki też istnieją.
Wyżej wymieniłem najważniejsze, potencjalne problemy, jakie można na siebie sprowadzić korzystając z rozwiązań open-source. Oczywiście nie należy generalizować i postrzegać wszystkich rozwiązań przez pryzmat tego typu kłopotów. Niemniej jednak zamiast entuzjastycznie skakać z radości, warto mieć świadomość ryzyka.
Osobiście boleśnie doświadczyłem pierwszego i czwartego z opisywanych problemów. W ramach pracy magisterskiej tworzyłem proste narzędzie do symulacji błędów działające w trybie jądra systemu Linux. Nie wnikając za bardzo w szczegóły, jest to rozwiązanie zbliżone koncepcyjnie do klasycznych debugger’ów, jednakże zamiast wykorzystywać API systemu operacyjnego (kwestie wydajnościowe w przypadku narzędzi programowej symulacji błędów) implementuje własne mechanizmy modyfikujące procedury obsługi przerwań poprzez patch’owanie kodu jądra “w locie”. Bazowym mechanizmem w tym rozwiązaniu jest ustawianie brakpoint’ów sprzętowych. Jądro udostępnia do tego celu elegancką funkcję register_user_hw_breakpoint. Super. Tylko, że ta funkcja, choć należy do API jądra od wersji 2.6.33 jest nieudokumentowana. Próżno szukać jej opisu na stronie dedykowanej API na kernel.org/doc. Jedynym dokumentem jest chyba artykuł z Linux Symposium dostępny w wielu miejscach w internecie (m.in. http://kernel.org/doc/ols/2009/ols2009-pages-149-158.pdf), który stanowi wstęp koncepcyjny autorstwa deweloperów odpowiedzialnych za implementację mechanizmu.
Aby funkcja utworzyła breakpoint sprzętowy na instrukcji wykonywalnej, jako wielkość należało jej podać stałą HW_BREAKPOINT_LEN_1. Tak było w wersjach jądra od 2.6.33 do 2.6.35. Problem zaczął się, gdy przetestowałem swój program na nowszych wersjach. Funkcja po prostu przestała działać. Nigdzie nie udało mi się znaleźć żadnych informacji, czy, jak i dlaczego interfejs uległ zmianie. Co gorsze, nigdzie w jądrze nie było wywołań tej funkcji z takim zestawem parametrów, jakiego używałem ja. Nie było więc niczego, na czym można by się wzorować. Przyznam, że straciłem sporo czasu analizując kod jądra w poszukiwaniu jakichkolwiek wskazówek, co mogło się stać. Miałem szczęście. Znalazłem. Okazuje się, że od wersji jądra 2.6.36 w przypadku pułapek sprzętowych, rozmiar musi być ustawiony jako sizeof(long), a nie jako wartość ww. stałej. Świetnie. Taka mała, ale niesamowicie złośliwa, nieudokumentowana, funkcjonalna zmiana w interfejsie API. Chyba jedna z gorszych rzeczy, jakie mogą spotkać programistę. Ale ja i tak miałem szczęście, moje rozwiązanie jest stosunkowo proste. Wywoływałem tę funkcję tylko 2 razy. Aż boję się pomyśleć co by było, gdyby coś takiego zdarzyło się podczas rozwoju naprawdę dużego projektu.
Zwolennicy open-source oraz członkowie społeczności deweloperów jądra mogą w tym miejscu zarzucić mi, że jestem amatorem, bo modyfikacja ta na pewno gdzieś jest opisana w jakimś commicie do repozytorium kodu jądra. A poza tym, to sam sobie jestem winien, bo interfejs programistyczny jądra jawnie nie gwarantuje kompatybilności pomiędzy różnymi wersjami jądra zarówno na poziomie funkcji jak i ABI. Owszem, wiem o tym. Tylko, czy to przypadkiem nie jest kolejne potwierdzenie, że stosowanie rozwiązań open-source może (oczywiście nie musi) wiązać się z dodatkowymi, nieprzewidywalnymi kłopotami?
Spotkałem się wielokrotnie z narzekaniami użytkowników systemu Windows, że po zastosowaniu hibernacji ich system zaczyna działać bardzo wolno i praktycznie nie nadaje się do użytku. Użytkownicy ci twierdzą, że problemy te są tak dokuczliwe, że nie korzystają z hibernacji w ogóle. W dzisiejszym wpisie chciałbym spojrzeć od strony technicznej na możliwe przyczyny takiego stanu rzeczy i zasugerować sposoby jeśli nie całkowitego, to przynajmniej częściowego zwalczenia problemu.
Na początku zwrócę również uwagę, że zdumiewająco mało osób korzysta z hibernacji i / lub usypiania komputera. Osobiście nie wyobrażam sobie życia bez tych dwóch opcji i nigdy (poza historyczną już wersją systemu Windows 2000, gdzie mechanizm hibernacji nie działał prawidłowo na wielu komputerach) nie doświadczyłem żadnych problemów z nimi związanych. Z użytkowego punktu widzenia często, gdy pracuję z użyciem kilkunastu aplikacji na raz, mając otwartych wiele różnych plików, to nie wyobrażam sobie codziennego uruchamiania i otwierania tego wszystkiego. Osobiście prawie nigdy nie wyłączam komputera zamykając jednocześnie system. Najczęściej usypiam komputer, w przypadku notebooka i odłączeniu go od zasilania zapewnia mu możliwość wykorzystywania akumulatorów, co jest dla nich dodatkowo korzystne. Gdy z jakichś przyczyn nie mogę uśpić komputera (akumulator jest zepsuty), a nie ma sensu usypiać laptopa podłączonego do prądu, wtedy używam hibernacji. Efekt końcowy jest w zasadzie identyczny.
W zasadzie, ponieważ, jak twierdzą niektórzy użytkownicy, po odhibernowaniu komputer zaczyna działać bardzo wolno. Kluczem do zrozumienia, dlaczego faktycznie komputer ma prawo zacząć działać wolno jest uświadomienie sobie pewnych specyficznych mechanizmów zarządzania pamięcią we współczesnych systemach operacyjnych, których działanie nie jest intuicyjne.
Hibernacja polega na zapisaniu zawartość używanej części pamięci fizycznej na dysk i wyłączeniu komputera. Wbrew pewnym opiniom, które napotkać można w Internecie, hibernacja z punktu widzenia sprzętowego powoduje takie samo wyłączenie komputera, jak opcja zamykania systemu. To system operacyjny jest odpowiedzialny za zrealizowanie całej operacji. Podczas normalnego działania systemu operacyjnego tylko część zarezerwowanej przez programy pamięci jest faktycznie zajmowana w pamięci fizycznej. Pozostała, ta mniej używana część jest przenoszona do pliku wymiany, na dysk twardy. W razie potrzeby, rzadziej używane fragmenty pamięci są “sprowadzane” z powrotem do pamięci fizycznej. Mechanizm ten nazywa się stronicowaniem na żądanie i pozwala na zoptymalizowane wykorzystanie pamięci fizycznej. Oprócz tego, gdy system operacyjny działa przez dłuższy czas, w pamięci fizycznej znajdują się nie tylko uruchomione programy, ale również bufor (ang. cache) operacji dyskowych. Bufor ten jest częścią pamięci fizycznej używanej przez system (ang. system working set) i podczas hibernacji jest zapisywany na dysk. Pamięć, która podawana jest w systemowym menedżerze zadań jako wolna w rzeczywistości też jest używana przez system. Jest tam tzw. standby list. Gdy system decyduje o przeniesieniu nieużywanej pamięci do pliku wymiany, owszem oznacza ją jako nieużywaną, ale zachowuje jej zawartość, tak na wszelki wypadek, gdyby trzeba było z niej szybko skorzystać (bo skorzystać można i tak, tylko, że sprowadzenie tego obszaru z pliku wymiany jest czasochłonne). Zarządzanie systemem buforowania w Windows wykonywane jest przy użyciu tego samego mechanizmu, który zarządza pamięcią. W związku z tym, część zawartości bufora plików, która przestaje być używana, również przenoszona jest do standby list, tak na wszelki wypadek, gdyby w przyszłości była potrzebna.
Gdy system działa przez dłuższy czas, standby list zapełnia prawie całą nieużywaną pamięć fizyczną, powodując, że wszystkie dane, które potencjalnie mogą być w każdej chwili potrzebne są obecne w pamięci fizycznej, do której dostęp jest bardzo szybki. Po długim działaniu komputera, mając uruchomione cały czas te same programy i wykonując takie same operacje, standby list w “inteligentny” sposób zapełnia pamięć komputera powodując płynne i szybkie działanie uruchomionych programów.
W tym momencie zbliżamy się do wyjaśnienia zagadki powolnego działania po odhibernowaniu. Przy hibernacji zapisywana jest tylko pamięć używana przez programy, czyli ta, która jest raportowana przez system jako faktycznie zajęta. Standby list nie jest zapisywana. Odhibernowany system musi ponownie załadować z dysku dane, które były zbuforowane w nieużywanej części pamięci. Nie ma możliwości wpłynięcia na zawartość standby list, więc w tym temacie niczego nie da się zmienić. Ale jest jeszcze jedno spostrzeżenie: gdy raportowane przez system zużycie pamięci jest duże, to zapewne plik wymiany również jest w znacznym stopniu wykorzystywany. Przed zahibernowaniem, jak wspomniałem, część danych przeniesionych na dysk do pliku wymiany znajduje się jeszcze w pamięci w standby list. Po zahibernowaniu i odhibernowaniu, wszystkie żądania sprawdzenia nieużywanych obszarów pamięci z pliku wymiany będą również skutkowały faktyczną operacją dyskową odczytu, co jest czasochłonne z punktu widzenia wykonywania programów. Jest to powód spowolnionego działania komputera po odhibernowaniu.
W jaki sposób tego uniknąć? Osobiście staram się nie hibernować systemu z bardzo dużym zużyciem pamięci. Dzięki temu przynajmniej częściowo eliminuję narzut czasowy potrzebny na sprowadzenie z pliku wymiany potrzebnych obszarów pamięci. Trudno podać mi konkretne liczbowe zalecenia, ale z moich doświadczeń wynika, że hibernowanie przy zużyciu pamięci mniejszym niż 50% nie powinno sprawiać absolutnie żadnych problemów po odhibernowaniu. Przed zahibernowaniem polecam więc użycie menedżera zadań, wybranie kilku najbardziej pamięciożernych aplikacji i zamknięcie ich. Najlepszymi, uniwersalnymi kandydatami na sam początek są przeglądarki internetowe, programy pocztowe i komunikatory. U mnie to działa.
PS. Problemy te nie dotyczą usypiania komputera, ponieważ wtedy zawartość pamięci fizycznej jest zachowywana (pamięć jest wtedy jedyną częścią komputera, która pozostaje zasilana).
Chciałbym przedstawić zdumiewające zagadnienie dotyczące obsługi bluetooth w tablecie Creative ZiiO 7. Co prawda jest to urządzenie z dolnej półki jeśli chodzi o tablety, niemniej jednak w mojej ocenie jest całkiem funkcjonalne. Niestety okazało się, że niektóre funkcjonalności są rozumiane przez producenta w nieco odmienny sposób niż mogłoby się to wydawać.
Problem dotyczy przesyłania plików z komputera do urządzenia poprzez bluetooth. Mówiąc krótko nie da się. Wysyłanie plików w systemie Windows kończy się błędem. Rzecz jasna, urządzenia są sparowane i “widzą się”. Co ciekawe, smartfon Nokia potrafi wysłać pliki do tabletu ZiiO bez żadnych problemów. Wystosowałem w tej sprawie następujące zapytanie do obsługi klienta firmy Creative:
I have a problem when connecting the device with 64-bit Windows 7 PC via bluetooth. The computer cannot send files to ZiiO. The configuration of computer OS is absolutely correct because it can clearly send files via bluetooth to Nokia smarphone. Furthermore, the Nokia smartphone can send files to the ZiiO, so it prooves that ZiiO is also properly configured. It seems that there is some issue with Microsoft bluetooth stack (i use default Windows tools to send files via bluetooth) and Android
Odpowiedź, którą otrzymałem jest jak następuje (podkreślenia moje):
May I know what file type have you transferred from your Nokia Smartphone to your ZiiO unit?
Was it transferred just by pairing the devices via bluetooth?
Please take note that the bluetooth feature of the ZiiO tablet is meant for streaming high fidelity stereo wirelessly to all compatible stereo Bluetooth speakers and headphones such as the ZiiSound D5, ZiiSound T6 and Creative WP-300 Headphones. It was never meant for file transferring.
Czy firma Creative jest w porządku? Formalnie tak, na jej stronie widnieje następujący opis feature’a tabletu związanego z bluetooth:
Bez przewodów, bez problemów - tylko nieskazitelna muzyka odtwarzana poprzez Bluetooth Dzięki wykorzystaniu technologii Bluetooth oraz apt-X urządzenie ZiiO 7” zapewnia wysoką wierność muzyki odtwarzanej bezprzewodowo. Urządzenie to może współpracować ze stereofonicznymi głośnikami Bluetooth - takimi jak głośniki Creative ZiiSound D5 oraz ZiiSound T6 - a także stereofonicznymi słuchawkami Creative WP-300.
(źródło: http://pl.store.creative.com/urzadzenia-multimedialne-odtwarzacze-mp3/ziio-7/948-20231.aspx)
Nie znam się na szczegółach technicznych implementacji stosu bluetooth. Niemniej jednak uwagę zwraca puste okienko usług dostępnych na sparowanym z komputerem tablecie:
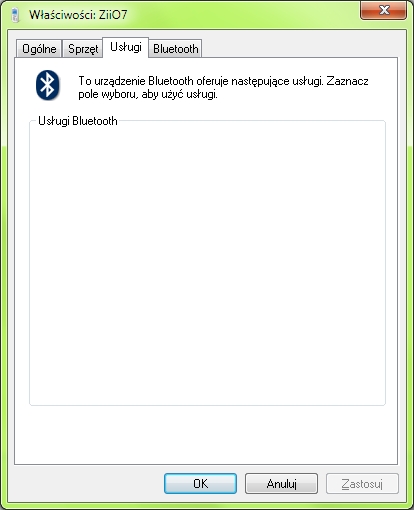
Poniżej lista usług smartfonu:
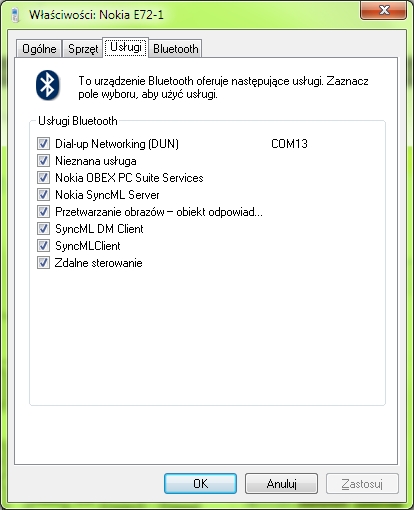
ZiiO jest tabletem pracującym pod kontrolą systemu Android w wersji 2.2. Funkcjonalność przesyłu plików przez bluetooth jest na standardowym wyposażeniu tego systemu, idę o zakład, że potrafi to każdy telefon z tym systemem. Wygląda na to, że firma Creative celowo zmodyfikowała implementację stosu bluetooth systemu Android tak, aby urządzenie nie obsługiwało żadnych usług bluetooth poza ich własną polegającą na jakimś niby cudownym przesyłaniu dźwięku.
Zagadnienie działającego przesyłu w kierunku smartfon Nokia -> tablet nie jest dla mnie do końca jasne. Być może implementacja stosu bluetooth w systemie Symbian jest tak skonstruowana, że rozpoczyna przesył pliku, nawet jeśli docelowe urządzenie nie “chwali się” tym, jakie usługi są na nim dostępne.
Chciałbym pogratulować z tego miejsca pomysłowości producentowi. Nie ma to jak zmodyfikować implementację technologii, która ma dziesiątki zastosowań tak, aby nadawała się tylko do jednego z tych zastosowań. Moim zdaniem producent powinien pójść w dokładnie przeciwnym kierunku i wręcz rozszerzyć obsługę bluetooth np. o dial-up networking, co umożliwiłoby podłączenie urządzenia do internetu poprzez dowolny telefon komórkowy. AFAIK nie jest to możliwe w systemie Android w wersji 2.2, natomiast coś takiego potrafi (co prawda po zainstalowaniu dodatkowego oprogramowania) konkurencja spod znaku jabłka – iPad. Oczywiście nie mam zamiaru załamywać się z powodu problemów z transferem, ponieważ istnieją rewelacyjne programy takie jak WiFi File Explorer, które umożliwiają przesyłanie plików szybciej i łatwiej niż przez bluetooth, niemniej jednak chciałbym zwrócić uwagę na niepokojący trend we współczesnej elektronice użytkowej polegający na tym, że producenci w coraz bardziej drastyczny sposób zaczynają ograniczać to, jak klient może używać ich produktu.
PS. Nie czuję się aż tak bardzo poszkodowany. Podobno konkurencja spod znaku jabłka też nie potrafi przesyłać plików przez bluetooth.
Z przygotowanego przeze mnie rozwiązania skorzystają zapewne tylko użytkownicy tego całkiem dobrego sprzętu do czytania ebook’ów. Jednakże, aby zachować wartość merytoryczną tego wpisu dla wszystkich czytelników, w drugiej części opisuję swoje spostrzeżenia i uwagi dotyczące tworzenia skryptów wiersza poleceń w systemie Windows.

2. Problemy przy rozwiązywaniu problemu, czyli pisanie skryptu wiersza poleceń
Gdy w różnych pseudo-fachowych poradnikach spotyka się porównania systemu Windows do systemu Linux to bardzo często zawarte są tam stereotypowe stwierdzenia, że w systemie Windows wiersz poleceń jest bezużyteczny, zaś w systemie Linux ma ogromne możliwości. W takich sytuacjach nie mogę oprzeć się refleksji, że autorzy takich porównań po pierwsze chyba nigdy sami nie napisali żadnego skryptu, a po drugie pewnie nie słyszeli, że od paru lat Windows ma Powershell, który jest de facto bardzo potężną powłoką. Poniżej postaram się pokazać kilka argumentów za tym, że standardowy interpreter poleceń systemu Windows jest jednak użyteczny, aczkolwiek ciężko.

2.1 Zapisywanie wyniku działania polecenia do zmiennej
Przykładowy przypadek użycia: wiemy, że w katalogu znajduje się plik wykonywalny (z rozszerzeniem .exe), ale nie wiemy jak się nazywa.
Kod cmd:
for /f %i in ('dir *.exe /b') do @set x=%i
echo %x%
Kod sh:
x=`ls *.exe`
echo $x
Jest to dziwactwo straszliwe: aby zapisać wynik do zmiennej trzeba. użyć pętli for. Koniecznie z przełącznikiem /f, który to umożliwia. Problem pojawia się, gdy wynik polecenia jest wielowierszowy. Przyznam, że nie zastanawiałem się nad tym, ale pewnie trzeba jeszcze bardziej kombinować. W powłoce Unix’a rzecz prosta i oczywista, bez żadnych dodatkowych komplikacji.
2.2 Różnice w semantyce poleceń
W cmd jest polecenie ren, które służy do zmiany nazwy pliku. W sh jest polecenie mv, które służy do przenoszenia plików, a w szczególności do zmiany ich nazwy. W sh w poleceniu mv możemy podać pełne ścieżki do plików. W ren ścieżkę podajemy tylko do pierwszego argumentu, drugi - czyli nowa nazwa musi być bez ścieżki. Żeby było ciekawiej w cmd jest też polecenie move, które działa tak samo jak mv z sh. Niby mało istotny szczegół, ale może spowodować nieoczekiwane wykolejenie się skryptu.
2.3 Liczenie w skrypcie
Przykładowy przypadek użycia: tworzenie zmiennych nazw plików w skrypcie.
Kod cmd:
set a=0
set /a a+=1
Kod sh:
a=0
a=`expr $a + 1`
Jak widać w cmd można liczyć. Polecenie set zostało unowocześnione i obsługuje teraz wyrażenia. Aczkolwiek, gdy ktoś tego nie wie i zabiera się za pisanie skryptu to jest mała szansa, że wpadnie na to, że trzeba użyć akurat polecenia set. Moim zdaniem język powłoki unixowej znów jest bardziej czytelny, prosty i logiczny. Używamy podstawowego mechanizmu: znaków akcentu i specjalnego polecenia, które służy do liczenia.
2.4 Podstawianie wartości zmiennych przez interpreter
Przykładowy przypadek użycia: wykorzystywanie w pętli for wartości pewnej zmiennej oraz modyfikacja tej wartości.
Kod cmd:
set a=0
for %s in (.\fixed_ebook\*.html) do (
set /a a+=1
echo %a%
)
Świetnie. Tylko, że ten kod nie działa. Trochę czasu i nerwów straciłem zanim dotarłem do wytłumaczenia zawartego w pomocy do polecenia set. Otóż interpreter cmd podstawia wartość zmiennej w momencie wczytywania linii z poleceniem, a nie jej wykonania. Wczytuje polecenie for, podstawia wartość zmiennej a i wykonuje. Dzięki temu wyświetlone zostaną same zera. Okazuje się, że trzeba użyć specjalnego dodatkowego polecenia, które “sprowadza interpreter na ziemię” i powoduje normalne (w sensie powłoki Unix’a) podstawianie wartości (trzeba jednak użyć znaków ! zamiast %).

W sh oczywiście takich niuansów nie ma, a pętlę for można nawet zapisać sobie w jednej linii, bo koniec poleceń oznacza się średnikiem (brakuje mi tego w cmd). Niemniej jednak ten prosty w świecie Unix’a chwyt z liczeniem jest również możliwy w systemie Windows.
Na koniec zwrócę jeszcze uwagę, że w przypadku wykonywania pętli for w skrypcie, trzeba użyć dwóch znaków % przy zmiennej. W przypadku wpisywania ręcznie w interpreterze trzeba użyć jednej. Niuans ten, jak i powyższe spostrzeżenia moim zdaniem wystarczają do tego, żeby stwierdzić, że pisanie skryptów w cmd jest męczące. Pominąłem tutaj zupełnie wspomniany na początku PowerShell, gdyż jest to całkiem inny język i niekoniecznie jest obsługiwany przez starsze wersje systemu Windows (w XP trzeba go doinstalować).
Gdy pracuję w systemie Linux i korzystam z mojego ulubionego klienta Bittorrent - Azureusa, często zachodzi potrzeba potraktowania tego programu poleceniami renice i ionice, żeby zwiększyć responsywność systemu, która mogła ucierpieć przez działanie złożonej Jav’owej aplikacji. Warto było w tym celu napisać sobie prosty skrypt. Pojawił się tutaj problem pobrania PID’u procesu na podstawie jego nazwy. Nie zagłębiając się specjalnie w naturę problemu (co okazało się błędem - o tym za chwilę) stworzyłem własne rozwiązanie tego problemu w ten sposób:
ps ax | grep "java.*Azureus" | awk {$0 = gensub(/legacy/blog/^ +/,"", "g", $0); print $1; exit}'
Dla zainteresowanych krótkie wytłumaczenie działania tej komendy:
ps ax - wyświetla listę wszystkich procesów użytkownika, również tych, które nie posiadają konsoli. Na początku każdego wiersza, tuż po spacji, jest szukany przeze mnie PID. Gdzieś pod koniec jest “command line” którym uruchomiono proces.
Odnajduję wiersz z procesem Jav’y, szukając słowa “java”, następnie dowolnej liczby dowolnych znaków, następnie słowa “Azureus”. Wzorzec ten “łapie” wiersz z procesem, którego szukam.
Następnie trzeba się jakoś pozbyć tej nieszczęsnej spacji na początku. Niestety prostym poleceniem cut nie dało rady, więc sięgnąłem po potężny AWK, który nadaje się idealnie, ponieważ przetwarza wierszami i od razu dzieli wiersz na rekordy. W “miniprogramie” AWK usuwam spację z początku wiersza “łapiąc” ją wyrażeniem regularnym “/^ +/” i usuwając. Następnie wypisuję pierwszy rekord wiersza, czyli szukany PID.
Jak widać powyższe rozwiązanie wbrew pozorom wykorzystuje sporo różnych pomysłów i w gruncie rzeczy nie wygląda na najprostsze. W tym momencie dochodzę do refleksji, która jest przedmiotem tego wpisu: otóż ktoś już wcześniej zauważył, że w życiu często zachodzi potrzeba znalezienia PID’u procesu po jego nazwie i wymyślono do tego oddzielne polecenie:
pgrep -f Azureus
Efekt jego działania jest dokładnie taki sam jak polecenia, które ułożyłem wcześniej. Wniosek z tego jest taki, że jeżeli zabieramy się za tworzenie własnego rozwiązania jakiegokolwiek problemu informatycznego (a może wcale nie tylko informatycznego), warto sprawdzić najpierw czy w danej chwili już nie dysponujemy narzędziami, którymi możemy ten problem rozwiązać natychmiast. Myślę, że przykładów podobnych, niezwykle użytecznych i mało znanych poleceń oraz funkcjonalności powłoki systemu Linux jest więcej, chociażby takie jak: watch, stat, column, reset czy mechanizmy zwane “event designator” albo “brace expansion”.
PS. Dla formalności dodam jeszcze, że podany wyżej “miniprogram” AWK też jest nadmiernie skomplikowany, bo okazuje się, że gensub nie jest potrzebny, samo "print $1" wystarczy :)
Wpis ten jest rozwinięciem zagadnienia opisanego tutaj. Krótkie przypomnienie: gdy utworzymy zbyt małą partycję wymiany może dojść do sytuacji, w której podczas próby hibernacji system zawiesza się. Jest to spowodowane niewystarczającą ilością miejsca na tej partycji. Gdy partycja wymiany jest w użyciu, znajdujące się tam wymiecione strony pamięci dodatkowo zmniejszają obszar potrzebny na zapisanie obrazu pamięci fizycznej. Przypomnę jeszcze, że stanowi to problem, dlatego, że jądro (bez dodatkowych zabiegów) nie potrafi zahibernować systemu przy użyciu pliku wymiany, a jedynie dedykowanej partycji. Poniższe rozwiązanie jest w pewnym sensie prowizoryczne, ale działa i pozwala na uniknięcie ryzykownych operacji zmienienia rozmiaru partycji.
Rozwiązanie polega na “zniechęceniu” systemu do korzystania z partycji wymiany, po to, aby było tam miejsce do zapisania obrazu pamięci fizycznej. Musimy jedynie świadomie hibernować system, tak, aby nie następowało to wtedy, gdy zużycie pamięci fizycznej przewyższa rozmiar tej partycji. Szczegóły przydatności tego rozwiązania zależą już od konkretnego przypadku - o ile za mała jest partycja wymiany. Ja ustawiłem tę wielkość na 1 GiB, dosyć trudno jest doprowadzić system do większego zużycia pamięci podczas wykonywania typowych czynności. W moim przypadku rozwiązanie okazało się więc wystarczające.
Tworzymy i włączamy dodatkowy plik wymiany, tak jak jest to opisane we wcześniejszym wpisie. Dodatkowo podajemy najwyższy możliwy priorytet dla nowego pliku wymiany opcją -p 32767. Dzięki temu system, gdy będzie chciał wymiatać strony na dysk w pierwszej kolejności zrobi to do nowego pliku wymiany, pozostawiając nietkniętą partycję wymiany, na której znajduje się cenna przestrzeń potrzebna do zapisania obrazu pamięci fizycznej.
Dodatkowo możemy sterować “wymiatalnością” stron pamięci. Parametr ten, jak sugeruje nazwa, określa jak często system ma wymiatać strony na dysk. 0 oznacza wyłączenie wymiatania; 100 oznacza, że system próbuje wymiatać jak najwięcej nieużywanych stron. Standardowo parametr ten wynosi 60. Ja ustawiłem go na liczbę jednocyfrową, po to, aby jak najwięcej używanej pamięci zmieścić w pamięci fizycznej i zobaczyć, czy zmieści się to w partycji wymiany podczas hibernacji. Sterowanie jest bardzo proste, modyfikujemy liczbę w systemie plików proc: /proc/sys/vm/swappiness. Polecam eksperymentowanie z tym parametrem, ponieważ można w ten sposób doprowadzić do zwiększenia wydajności systemu zmuszając go do odwlekania z korzystania z pliku wymiany tak długo jak tylko jest to możliwe.
Zaobserwowałem trudno powtarzalny problem pojawiający się przy próbie zahibernowania linuksa Ubuntu. Nie będę się rozpisywać o zaletach używania hibernacji - dla mnie to bardzo praktyczna opcja pozwalająca skrócić czas “włączania” komputera. Jestem przyzwyczajony do tego, aby natychmiast mieć uruchomione wszystkie programy z których korzystam na co dzień. Problem polegał na tym, że czasami podczas hibernowania system zamiast wyłączyć komputer wyświetlał na ekranie szereg enigmatycznych komunikatów, z których jedyne, co było zrozumiałe to fakt, że coś się zawiesiło. Jedyne co można było zrobić to wcisnąć magiczną kombinację [ALT]+[Print Screen]+[R]+[S]+[I]+[U]+[B] powodującą synchronizację buforów dyskowych, odmontowanie systemu plików i bezpieczny restart (szczegółowy opis tej linuksowej sztuczki jest np. tutaj, odpowiednika w systemie Windows niestety brak)
Stwierdziłem, że nie można tego problemu tak zostawić i zacząłem poszukiwać informacji na temat jego przyczyny. Po drodze trafiłem na fajne alternatywne narzędzia pozwalające na zahibernowanie bądź uśpienie systemu z konsoli: http://en.wikipedia.org/wiki/Uswsusp - polecam. Niemniej jednak również s2disk powodował identyczne zawieszenie się systemu.
Po dłuższych poszukiwaniach udało mi się ustalić, że przyczyną jest bardzo dziwny mechanizm hibernacji stosowany w jądrze linuksa - zupełnie odmienny od tego co jest stosowane w systemie Windows. System linuks zapisuje obraz pamięci do… no właśnie - właściwie na… partycję swap. Nietrudno się domyślić, że gdy swap jest w większości zajęty to nie ma tam miejsca na zapisanie zawartości pamięci fizycznej. Rozwiązanie z oddzielnym plikiem o rozmiarze równym pamięci fizycznej i przeznaczonym wyłącznie do hibernacji w systemie Windows jest o wiele lepsze. Swoją drogą, warto zwrócić uwagę, iż pomimo posiadania dużej ilości pamięci RAM nie warto ograniczać (nie mówiąc już o rezygnacji - słyszałem, że niektórzy użytkownicy tak robią) rozmiaru partycji swap.
Całe szczęście, że jądro linuksa umożliwia określenie dowolnego pliku jako dodatkowej przestrzeni swap. Problem rozwiązałem dodając sobie (trochę na zapas) dodatkowe 3 GiB przestrzeni swap:
dd if=/dev/zero of=/swap3gb bs=1024k count=4000
mkswap /swap3gb
swapon /swap3gb
Można to w każdej chwili wyłączyć:
swapoff /swap3gb
rm /swap3gb
Niestety jak się okazało problemu nie rozwiązałem. Sprawa jest znacznie bardziej skompilowana niż mi się wydawało. Istnieją 2 mechanizmy pozwalające na hibernowanie systemu Linux:
Pierwszy z nich jest zaimplementowany w jądrze od wersji 2.6, drugi stanowi łatę na kod jądra i co za tym idzie wymaga jego rekompilacji. Pierwszy z nich jest standardowo używany w systemie i nie obsługuje zapisywania obrazu pamięci przy hibernacji do obszaru swap zdefiniowanego w pliku. Istnieje dość złożony sposób pozwalający na wybudzenie się ze swap’a w pliku polegający na modyfikacji ustawień initfs oraz grub’a. Polega on na odczytaniu fizycznego numeru bloku dyskowego pliku i podania go jako parametr jądra. Szczegółowy opis jest tutaj. Obecnie jestem w trakcie testowania pewnej sztuczki, która być może pozwoli na prostsze rozwiązanie problemu (coś jednak spowodowało, że po dodaniu pliku swap system na kilkadziesiąt hibernacji zawiesił się tylko raz). Jeżeli mój pomysł się sprawdzi oczywiście go opiszę.
Musiałem ostatnio pozbyć się polskich znaków z pliku tekstowego pracując w systemie Linux. Z pewnością jest sporo sposobów, ale ponieważ nie chciało mi się szukać wymyśliłem własny. Kilka lat temu spisałem kody wszystkich polskich znaków w Windows-1250, ISO-8859-2 i UTF-8. Dokument ten umieściłem tutaj. Aby usunąć polskie znaki wystarczy użyć polecenia tr, które idealnie się do tego nadaje, umieszczając kody znaków (ósemkowo) jako ciąg do zamiany. Zakładam, że mamy do czynienia z kodowaniem ISO-8859-2 - z UTF-8 nie chciało mi się kombinować, ze względu na 2-bajtowe kody znaków, co trochę skomplikowałoby polecenie. Zapisu do ISO-8859-2 można dokonać w większości edytorów tekstowych dostępnych w systemie Linux. Skrypt usuwający polskie znaki przy takich założeniach wygląda tak:
#!/bin/sh
cat $1 | tr '\277\363\263\346\352\266\261\274\361' zolcesazn > $1
PS. Bardziej zaawansowanym narzędziem do manipulacji kodowaniem jest polconv.
Banalna czynność. Wszyscy przesyłają pliki przez Internet. Jednakże prostota tej czynności jest odwrotnie proporcjonalna do liczby plików i/lub ich objętości. Ostatnio musiałem przesłać ok. 600 plików o łącznej objętości ok 2 GiB. Są to wielkości przy których “wymiękają” powszechnie znane rozwiązania. Poniżej krótkie zestawienie rozważanych sposobów przesyłania plików oraz opis tego, które zdecydowałem się zastosować.
Poczta elektroniczna. Odpada jeśli chodzi o duże pliki. Co prawda współcześni dostawcy darmowych skrzynek kuszą pojemnościami rzędu kilku GiB, ale powiedziałbym, że jest to w pewnym sensie iluzja. Owszem mamy tyle do dyspozycji, ale mało kto będzie w stanie nam tyle wysłać - chyba wszyscy dostawcy stosują ograniczenia wielkości wysyłanego listu, przykładowo GMail - 25 MiB - jest to słuszne i uzasadnione ochroną przed automatami wysyłającymi spam. Dostawcy płatnych rozwiązań np. home.pl nie stosują ograniczeń wielkości wysyłanej przesyłki, ale są raczej mało popularni w kategorii skrzynek pocztowych. Moim zdaniem poczta nadaje się do przesyłania plików o względnie małej wielkości rzędu kilku MiB.
Serwis hostingowy typu Rapidshare, 4Shared, Drop.io etc. Odpada jeśli chodzi o duże pliki, dodatkowo kwestia upublicznienia materiału, który chcę przekazać w sposób poufny. Należałoby użyć szyfrowania. Dodatkowy kłopot - rozwiązanie bez sensu.
Serwis przesyłający plik w czasie rzeczywistym typu filesovermiles.com czy jetbytes.com. Odpada jeśli chodzi o duże pliki. Co prawda serwisy te uważam za rewelacyjną usługę ułatwiającą przesył plików, jednakże ze względu na pośredniczącą rolę serwera wprowadzany jest spory narzut na szybkość (jetbytes.com - szybkość ok. 20 KiB/sek, to bardzo niewiele). Wolałbym z resztą rozwiązanie, które umożliwi mi wznowienie przerwanego transferu.
Przesył plików w komunikatorze internetowym. Odpada w ogóle. Konia z rzędem temu, komu ta funkcjonalność w ogóle działa w najpopularniejszym w naszym kraju komunikatorze. W przypadku klienta za NAT’em można zapomnieć o przesłaniu pliku do znajomego przez GG.
Postawienie własnego serwera FTP. Odpada - za duży kłopot. Problem z wyborem łatwego w obsłudze i bezpiecznego serwera. Ponadto wystawianie otwartego portu FTP na świat nie jest najlepszym pomysłem ze względów bezpieczeństwa - należałoby dokładnie skonfigurować konto użytkownika i poustawiać zabezpieczenia. Dodatkowo można narazić się na atak DoS. Domowy komputer z systemem Windows nie jest maszyną dobrze przygotowaną do roli serwera.
Jak widać jestem wymagający ;). Rozwiązaniem, które okazało się satysfakcjonujące jest program do tworzenia VPN o nazwie Hamachi razem z programem kopiującym foldery Microsoft Robocopy. Hamachi umożliwia stworzenie wirtualnej prywatnej sieci lokalnej zabezpieczonej hasłem. W systemie widoczny jest jako dodatkowa karta sieciowa. Cały ruch po tej karcie w rzeczywistości jest tunelowany przez szyfrowane algorytmem AES połączenie do serwera Hamachi albo bezpośrednie połączenie do peer’a nawet znajdującego się za NAT’em (Hamachi potrafi automatycznie skonfigurować przekierowania portów w urządzeniu sieciowym) . W praktyce, od strony użytkownika wygląda to tak jakby była zwyczajna sieć lokalna. Transfer plików odbywa się poprzez folder udostępniony Windows przy użyciu programu kopiującego Robocopy. Jest to zaawansowane narzędzie do kopiowania plików, które wyświetla bogate statystyki oraz ma bardzo duży zestaw opcji - w tym możliwość wznawiania przerwanego transferu. Oto co udało się zyskać:
Bezpieczeństwo - połączenie jest szyfrowane i w większości przypadków ustanowione bezpośrednio do innego komputera (jeżeli nie udało się ustawić przekierowania portów, wówczas połączenie jest pośrednio przez serwer Hamachi - te szczegóły techniczne konfigurują się automatycznie bez ingerencji użytkownika). Nie muszę się martwić, że ktoś podejrzy zawartość przesyłanych plików. Nie muszę ich dodatkowo zabezpieczać.
Szybkość - co prawda serwer pośredniczący Hamachi również wnosi pewien narzut szybkościowy, ale w praktyce udało się uzyskać prędkości rzędu 100 KiB/sek przy wysyłaniu, co było satysfakcjonujące.
Wygoda - przeglądanie zawartości udostępnianych katalogów przy użyciu standardowych narzędzi. Nie muszę kompresować plików ani poddawać ich innym zabiegom.
Dokładne informacje o postępie kopiowania - informacje podawane w trakcie działania Robocopy są bardzo bogate
Możliwość przerwania i wznowienia transmisji w dowolnej chwili
Automatyzacja działania - Robocopy zachowuje się “inteligentnie” w przypadku chwilowych problemów z siecią i wielokrotnie ponawia próby kopiowania. Po uruchomieniu tego narzędzia można spokojnie zająć się czymś innym - przy ustawieniach domyślnych program nie poddaje się przy pojedynczym błędzie tylko czeka 30 sek. a następnie ponawia próbę - i tak milion razy (parametry te można ustawić)
Poniżej zrzut ekranu z konsoli po zakończonym transferze Robocopy. Szybkość jest tu mniejsza niż wspominane 100 KiB/sek ponieważ transfer odbywał się z maszyny o łączu 32 KiB/sek - jak widać “tunelowanie” zabiera ok. 4 KiB/sek - tutaj mamy statystyki z poziomu łącza VPN, na poziomie rzeczywistego połączenia do peer’a szybkość wynosiła w przybliżeniu właśnie 32 KiB/sek.
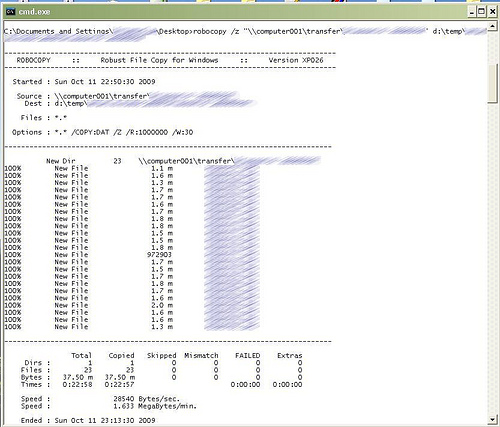
PS. Hamachi jest szeroko stosowanym rozwiązaniem wśród amatorów gier działających w sieci lokalnej. Znakomicie nadaje się do “zwirtualizowania” sieci lokalnej wszędzie tam gdzie istnieje taka konieczność, a dysponujemy tylko łączem internetowym.