Pod koniec lutego 2019 roku, niemalże dokładnie 10 lat od chwili powstania mojego bloga, otrzymałem wiadomość o zamknięciu serwisu blox.pl, które nastąpi pod koniec kwietnia. Decyzja ta nie jest nieoczekiwana, ponieważ wraz z rozwojem współczesnych technologii, blox.pl stawał się coraz bardziej reliktem minionej już epoki, pierwszej dekady XXI wieku, czasów, gdy pojęcie mediów społecznościowych jeszcze nie zostało nawet zdefiniowane.
Świadectwem tamtej epoki są również wpisy na moim blogu, które postanowiłem zachować i zmigrować w miejsce, nad którym posiadam kontrolę. Niektóre z tych wpisów są już całkowicie nieaktualne (jak np. dywagacje dot. niuansów serwisu Nasza Klasa), inne znajdują zastosowanie przeze mnie osobiście do dzisiaj (jak np. sposób zabezpieczania profilu przeglądarki, czy zasady bezpiecznego korzystania z internetu).
Opiszę krótko kilka ogólnych, technicznych aspektów migracji:
- Ponieważ od 2013r. prowadzę nowy blog tylko o tematyce technicznej blog.pjsen.eu w języku angielskim, dlatego chciałem uniknąć przeniesienia treści starego bloga bezpośrednio do infrastruktury nowego.
- Blox.pl udostępnia zawartość treści bloga w postaci współczesnego formatu eksportu z WordPress’a.
- Najprościej byłoby zaimportować tę treść po prostu do nowego bloga opartego na WordPress, ale zarządzanie dwoma blogami to jest coś, czego chciałem uniknąć. Zależało mi na odizolowaniu starych treści w innym miejscu w możliwie najprostszy do wykonania i utrzymywania sposób.
Wymagania te zostały zrealizowane w następujący sposób:
- Jako technologię utrzymywania treści bloga wybrałem tzw. statyczny generator stron o nazwie Hugo.
- Statyczne generatory umożliwiają wytworzenie całej witryny internetowej na podstawie łatwo edytowalnych plików, zazwyczaj w formacie Markdown. Wygenerowana witryna jest w całości statyczna, można ją hostować wszędzie. Hugo jest dość dobrym generatorem, ponieważ składa się z pojedynczego pliku exe, a jego podstawowa obsługa ogranicza się praktycznie do uruchamiania
hugo, hugo server i hugo new. Na stronie głównej można przeglądać bardzo bogaty katalog gotowych do użycia szablonów.
- Aby przekonwertować treść do formatu Markdown użyłem Exitwp — skryptu napisanego w Pythonie 2.7. Niestety konieczna była ręczna modyfikacja tego skryptu, ponieważ spodziewał się on kilku elementów struktury xml, które nie były obecne w wyeksportowanej treści z blox.pl. Na szczęście, metodą zaledwie kilku prób i błędów usunąłem niepotrzebne linie ze skryptu, a inne brakujące wartości udało mi się zastąpić zaślepkami np. jako
wordpress_id ustawiałem 0, ponieważ celem było tylko zmuszenie skryptu do przekonwertowania treści, a nie zachowania pełnej struktury metadanych.
- Odniesienie do zasobów statycznych zawierały w ścieżce podkatalog, a Hugo zakłada, że będą one obecne na stronie głównej. Przy pomocy jednolinijkowego skryptu języka Perl i wyrażeń regularnych zmieniłem ścieżki do obrazków i plików we wszystkich 51 plikach wpisów:
-
find . -iname '*.markdown' -exec perl -pi -w -e 's/(\(resources\/)(.*)/\(\/$2/g' {} \;
- Wpisy poddałem ręcznej korekcie w programie MarkdownPad. Zmodyfikowałem też układ strony, na swoje potrzeby. Pewną nieoczekiwaną dla mnie ciekawostką okazał się atrybut
integrity tagu z odniesieniem do styli CSS. Była to suma kontrolna ustawiona sztywno na wartość wygenerowaną w momencie kompilacji szablonu. Ja zmodyfikowałem szablon, konieczne było więc usunięcie tego atrybutu (generowanie poprawnej wartości nie było do niczego potrzebne).
- Niestety nie przekonwertowałem linków do wpisów w obrębie bloga. Nie miałem oczywistego pomysłu, jak zrobić to automatycznie ani czasu, żeby robić to ręcznie.
Na koniec, w celach pamiątkowych, wklejam zrzut ekranu starego bloga z momentu na chwilę przed jego likwidacją:
Jestem użytkownikiem programów tworzonych przez fundację Mozilla od 2003 roku. W tamtym czasie główną przeglądarką była Mozilla Suite, rok później pojawił się Firefox korzystający z tego samego silnika, ale z kompletnie przebudowanym interfejsem użytkownika. Przez ten czas wielokrotnie migrowałem swój przeglądarkowy profil, ale zawsze zachowywałem zakładki. Niektóre z nich pamiętają jeszcze czasy sprzed Firefox’a, aczkolwiek większość z takich właśnie zapewne prowadzi już do nieistniejących stron. Przez cały ten czas uzbierałem nieco ponad 1000 zakładek. I to właśnie jest problem.
Dotychczas miałem kilka podejść do uporządkowania tego zbioru. Próbowałem ręcznie wyszukiwać nieaktualne zakładki, całość pogrupować w foldery. Próbowałem też korzystać ze słów kluczowych i opisów, żeby później móc efektywniej wyszukiwać. Ale rezultat był raczej mizerny. Zanim napisałem ten post miałem kilkanaście folderów, ale gdy przychodziło do wyszukiwania czegoś zawsze pojawiał się ten sam problem: pamiętam, że znalazłem jakąś istotną dla mnie stronę, pamiętam czego ona dotyczyła i pamiętam też, że na pewno dodawałem ją do zakładek. Ale nie jestem w stanie jej odnaleźć w tych zakładkach. Albo z powodu nie pasującego tytułu, albo dziwnych, nie nawiązujących do treści słów w adresie (a tylko według tych kryteriów możemy wyszukiwać).
Potrzebowałem narzędzia do wyszukiwania, które ma znacznie większą “moc” niż standardowe wyszukiwanie w przeglądarce. Ponieważ nie udało mi się znaleźć niczego takiego, to stworzyłem je sam. Narzędzie to nazwałem BookmarksBase. Jest to otwarto-źródłowy program napisany w języku C#.
Program realizuje pomysł, który może początkowo wydawać się niedorzeczny: spróbujmy pobrać tekst ze wszystkich stron internetowych z zakładek. Czy to będzie zajmowało dużo miejsca? Jak dużo? Czy nawet jeśli byłyby to setki megabajtów, to nie byłoby warto mieć narzędzie do przeszukiwania tej treści?
Okazuje się, że taki zbiór danych wcale nie zajmuje tak dużo miejsca, jak początkowo mi się wydawało, a samo narzędzie działa zaskakująco szybko, pomimo tego, że nie próbowałem stosować żadnych wyrafinowanych optymalizacji.
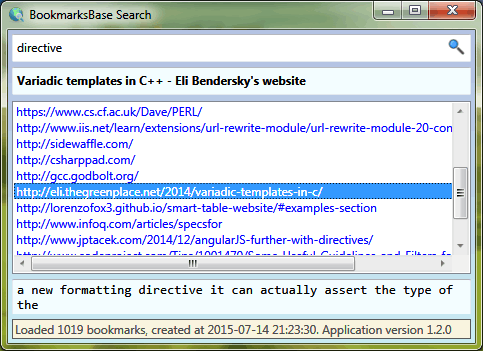
Narzędzie składa się z kilku programów. Najpierw uruchamia się program zbierający adresy stron internetowych z zakładek (BookmarksBase.Importer). Pobieranie i przetwarzanie zawartości stron w moim przypadku trwało ok. 2 minut (przypominam, że chodzi o sam tekst, w moim przypadku jednak z dość dużej liczby ok 1000 zakładek). W wyniku tworzony jest plik bookmarksbase.xml (w moim przypadku ok 12 MiB) zawierający tekst ze wszystkich stron, w postaci czytelnej dla dowolnego programu. Następnie do właściwego wyszukiwania służy BookmarksBase.Search, który pełni rolę przeglądarki dla utworzonego pliku. Wyszukujemy dowolny tekst, a program znajduje go w treści, adresie lub tytule i wyświetla wszystko jednocześnie.
Szczegóły oraz link do pobierania dostępne są na moim koncie GitHub.
W momencie publikacji tego wpisu program znajduje się w wersji stabilnie działającej, ale planuję wprowadzić jeszcze kilka udoskonaleń np. wyświetlanie listy nieaktualnych zakładek przez importer oraz usprawnienie nawigacji po BookmarksBase.Search przy użyciu klawiatury.
Publikuję trywialny program pełniący rolę “gadżetu pulpitu” i wyświetlający aktualną temperaturę w Warszawie na podstawie serwisu http://www.meteo.waw.pl. Stworzony na własne potrzeby, być może dla kogoś z Odwiedzających również okaże się przydatny.
Program automatycznie odświeża się co 5 minut. Można to zmienić w załączonym pliku konfiguracyjnym .config.
Program jest skompilowany dla Microsoft .NET w wersji 4.5.1.
Wkrótce opublikuję również kod źródłowy na GitHub. Dzięki zastosowanym rozwiązaniom oceniam, że ewentualna modyfikacja pod kątem użycia innych źródeł danych powinna być bardzo prosta.

Link do pobrania
Wersja z dnia 2015-04-23
AKTUALIZACJA: Kod źródłowy jest do pobrania pod adresem https://github.com/przemsen/WebThermometer
Osobiście korzystam z trzech serwisów związanych z pogodą, które w mojej ocenie publikują bardzo dobre prognozy i użyteczne informacje. Często jestem pytany o adresy tych stron, więc podzielenie się tymi informacjami powinno być dobrym pomysłem.
1. meteo.pl (UM)
Prognoza opracowywana przez Interdyscyplinarne Centrum Modelowania Matematycznego Uniwersytetu Warszawskiego. Jest to co innego niż widzimy w większości mediów. Prognoza potrafi przewidzieć opady co do godziny, według mojej subiektywnej opinii bardzo wysoka sprawdzalność.
Bezpośredni link do prognozy dla Warszawy.
- meteo.waw.pl
Stacja meteorologiczna umiejscowiona w Warszawie, w dzielnicy Ursus. Częściej otwieram tę stronę niż patrzę na fizyczny termometr za oknem. Adres przydatny nie tylko dla mieszkańców Warszawy, ponieważ zawiera linki do innych stacji.
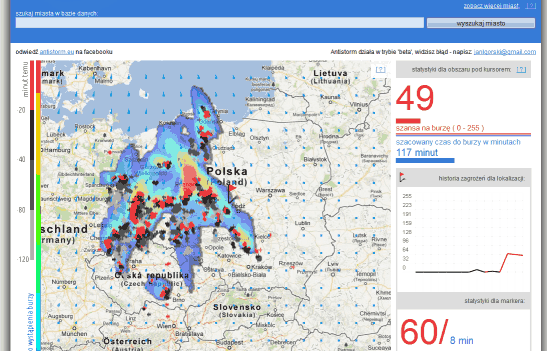
- antistorm.eu
Wizualizacja prawdopodobieństwa wystąpienia burzy na terenie całej Polski. Jedna z bardziej użytecznych, jakie widziałem.
I have decided to publish new blog posts only in English. I have always been trying to provide information that can be useful for other people. Writing only in Polish language hinders me from reaching my target audience. Which can potentially be everywhere, not only in my country. In my experience I have already come across situations when I find something useful and cannot benefit from it, because it is written only in German or only in Italian. I would not like to make such mistakes. English language is the most appropriate tool for establishing connection with and reaching people worldwide. I also do believe my Polish readers will not suffer much  as knowledge of English in my country is not too bad.
as knowledge of English in my country is not too bad.
UPDATE – March 18, 2013. I have started new technical blog: blog.pjsen.eu. All new technical content will be published there in English. Here some minor, Polish-specific thoughts will be shared.
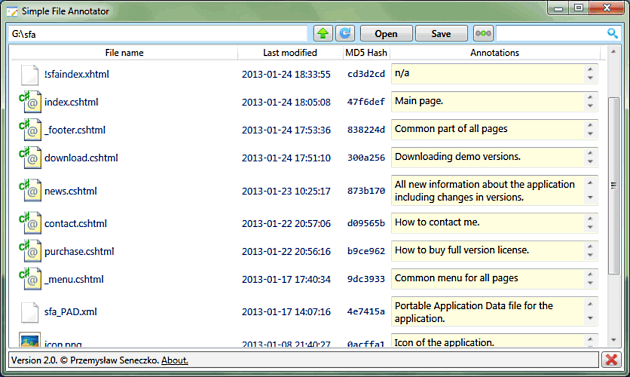
Jest to problem, którego doświadczyłem osobiście wiele razy. Szczególnie podczas pisania prac dyplomowych, ale również na co dzień. Mam bardzo dużo materiałów w postaci dokumentów PDF z artykułami, prezentacji, e-boook’ów itd. Po pewnym czasie pojawia się problem skojarzenia co właściwie jest najważniejsze w danym pliku. Długa nazwa nie rozwiązuje tego problemu. Idealne byłoby narzędzie, które wyświetla zawartość plików w katalogu, a po prawej stronie daje możliwość przypisania dowolnego tekstu do danego pliku. W ten sposób można by np. opisać sobie w punktach najważniejsze rzeczy w dokumencie. Ale zastosowań takiego narzędzia byłoby więcej: opisywanie zdjęć, tworzenie list rzeczy do zrobienia, napisanie krótkiej informacji jak działa program narzędziowy itp.
Poszukiwałem takiego narzędzia, ale niestety nie udało mi się znaleźć niczego, co byłoby wystarczająco proste i skuteczne. Owszem, istnieją zaawansowane narzędzia zarządzania dokumentami jak np. Benubird. Ale czemu ograniczać się tylko do dokumentów PDF? Istnieją też systemy wspomagające zarządzaniem dokumentów ukierunkowane na pisanie prac naukowych, wspomagające tworzenie bibliografii, przypisów, cytowań itd. np. Mendeley. To potężne i cenione narzędzie. Ale w mojej ocenie, zastosowanie go do realizacji ww. prostych wymagań przypomina celowanie armatą do wróbla.
Postanowiłem więc samodzielnie stworzyć program spełniający tak postawione wymagania. Nazwałem go Simple File Annotator. Myślę, że jest to rozwiązanie dość unikatowe, bardzo elastyczne - ponieważ może być wykorzystywane do bardzo różnych zastosowań. Zapraszam na stronę:
http://www.pjsen.eu/sfa
Na koniec kilka słów wyjaśnienia, dlaczego podjąłem decyzję, aby projekt ten miał charakter komercyjny. Osobiście bardzo potrzebowałem takiego narzędzia. Byłem gotowy nawet za nie zapłacić, gdyby tylko istniało. Ale nie istniało (przynajmniej nic mi o tym nie było wiadomo). Oceniam, że pomysł ten może stanowić pewną wartość, dla użytkowników, którzy doświadczyli i rozumieją, na czym polega problem opisany we wstępie. Cenę ustaliłem taką, jaką uwzględniając zdrowy rozsądek, sam byłbym w stanie zapłacić za tego typu program. Jest to bardzo niska cena jak na oprogramowanie, prawdę powiedziawszy widziałem w Internecie mniej skomplikowane programy sprzedawane za wyższą cenę. Mam więc nadzieję, że efektywny zysk dla użytkownika ze stosowania tego narzędzia będzie i tak większy niż mój czysto liczbowy zysk jako producenta.
W najbliższym czasie przedstawię kilka spostrzeżeń i wniosków związanych z narzędziami, które warto wykorzystywać podczas prac nad jakimkolwiek większym projektem. Niekoniecznie informatycznym. Niekoniecznie pracą dyplomową. Ponieważ sam dosyć długo eksperymentowałem, zanim odnalazłem (w mojej ocenie) najbardziej efektywne rozwiązania, chciałbym podzielić się wnioskami, które czytelnik mógłby bezpośrednio wykorzystać, żeby ułatwić sobie życie. Dzisiejszy post jest pierwszym w serii omawiającej 3 zagadnienia: LaTeX, system kontroli wersji, narzędzie do tworzenia kopii zapasowych.
Używanie LaTeX’a
Na wstępie dwa słowa, jeżeli ktoś z czytelników nigdy nie słyszał tej nazwy. Generalnie, wszystkie powszechnie znane edytory tekstu działają na zasadzie WYSIWYG, What You See Is What You Get. Edytuje się tekst, który jest rozmieszczony na stronie. Po wydrukowaniu uzyskuje się dokładnie to samo, co było na ekranie. LaTeX to zupełnie odmienne podejście. Wygląd dokumentu opisywany jest za pomocą komend. Za rozmieszczenie tekstu tak, jak to zostało zadeklarowane, odpowiada program kompilujący LaTeX, który jako rezultat, powiedzmy w uproszczeniu zwraca dokument PDF.
Na temat LaTeX’a istnieją jedynie skrajne opinie. Albo ktoś go nie używa i uważa za wariatów ludzi, którzy zaśmiecają sobie umysł jakimiś komendami, zamiast po prostu uruchomić Word’a; albo ktoś go używa i nie wyobraża sobie pisania dłuższych tekstów w innym narzędziu. Sam przeszedłem ewolucję od pierwszego do drugiego “typu” ludzi. W mojej ocenie, LaTeX w znaczący sposób ułatwia pracę nad długim tekstem i ma szereg zalet w porównaniu do klasycznych edytorów. Początkujący użytkownik napotyka jednak na kilka problemów, z których pierwszym jest wybór edytora.
Osobiście próbowałem używać różnych narzędzi, np. TeXnicCenter, Kile czy LEd, ale wszystkie one wydawały mi się skomplikowane i nieintuicyjne. LyX z kolei, moim zdaniem nakłada zbyt wiele ograniczeń na ogromne możliwości LaTeX’a. Wielu profesjonalistów używa po prostu Vim’a, ale moim zdaniem do wygodnej pracy potrzebnych jest wiele funkcjonalności oferowanych przez specjalistyczne edytory. Mam na myśli np. automatyczne wyświetlanie podglądu struktury dokumentu, sprawdzanie pisowni, zwijanie bloków kodu, dostępność “na wyciągnięcie ręki” najczęściej używanych komend itd. Narzędziem, które sam wybrałem i gorąco polecam jest TeXStudio. Oferuje on duży zbiór funkcjonalności, ma intuicyjny i zdumiewająco prosty w obsłudze interfejs oraz pozwala na szybką i łatwą konfigurację sprawdzania pisowni “w locie”. Moim zdaniem wielką zaletą tego narzędzia jest to, iż po bardzo krótkim zapoznaniu się z nim, można rozpocząć wydajną pracę. Gdy mamy już edytor, możemy przejść do konkretów - dlaczego LaTeX jest lepszy od tradycyjnych edytorów:
Bardzo precyzyjna kontrola nad strukturą dokumentu. Wszelkie zmiany typu przesunięcie rozdziału do podrozdziału czy zmiana lokalizacji w strukturze dokumentu wykonują się bezboleśnie.
W ogóle bardzo precyzyjna kontrola nad formatowaniem. W przypadku edytorów klasycznych, bardzo często zdarza się, że edytor zwyczajnie odmawia wykonania tego, co byśmy chcieli, żeby zrobił. Sam widziałem sytuację gdy Microsoft Word uparł się, że w dość długim dokumencie, na każdej stronie każdy pierwszy akapit miał zmniejszone marginesy w stosunku do reszty tekstu. Nie było żadnej możliwości, aby przekonać program, żeby to zmienił. W LaTeX’u takie rzeczy się nie zdarzają.
Gdy wszystko jest już ustawione, można jedynie pisać swój tekst i nie martwić się, jak to będzie wyglądać. Ty koncentrujesz się jedynie na merytorycznej stronie pracy. Resztą zajmie się LaTeX. Używanie LaTeX’a jest jak zatrudnienie specjalisty od składania tekstu, który wykonuje dla nas czarną robotę za friko. Twój tekst zostanie tak rozmieszczony na stronach, że będzie wyglądał profesjonalnie.
Jeżeli potrzebujesz pisać nietypowo sformatowane rzeczy, w dodatku zagnieżdżane jedne w drugich, np. wielokrotne wypunktowania z wklejonymi wyróżnianymi fragmentami od nowej linii (np. kod), to bardzo szybko docenisz potęgę LaTeX’a. Tego typu rzeczy po prostu działają. Nigdy nie zepsują Ci układu dokumentu. Będą wyglądać dokładnie tak, jak chcesz.
Gdy zapragniesz dodać ilustrację w środku tekstu, również masz gwarancję, że nic w układzie tekstu “nie rozjedzie się”.
Masz pełną, w dodatku bardzo szybką i wygodną kontrolę nad odnośnikami do czegokolwiek w tekście. Dzięki tekstowym etykietom odnośników, na pierwszy rzut oka wiesz, do czego prowadzi odnośnik.
Dokument jest czystym plikiem tekstowym, w związku z tym można na nim wykonywać dowolne operacje klasycznymi narzędziami jak grep/sed/awk/diff.
Gdy w gotowym już dokumencie musisz wprowadzić jakiekolwiek zmiany, również nie musisz obawiać się, że cokolwiek “się zepsuje”.
Dysponujesz gotowymi szablonami różnych typów dokumentów. Nie musisz martwić się jak powinna wyglądać książka, raport czy list. Po prostu używasz odpowiedniej klasy.
Jeżeli uważasz że większość prezentacji wykonanych przy użyciu Microsoft PowerPoint wygląda mało profesjonalnie, to poczytaj sobie o klasie Beamer. To zupełnie nowa jakość jeśli chodzi o estetykę prezentacji.
Dokumenty można edytować i kompilować na różnych systemach operacyjnych. TeXStudio działa bezproblemowo w systemie Microsoft Windows 7 i Linux.
Osobiście byłem pełen obaw, zanim podjąłem decyzję o pisaniu pracy magisterskiej w LaTeX’u. Mam porównanie, ponieważ pracę inżynierską pisałem w OpenOffice Writerze. Decyzja o wybraniu LaTeX’a była jednak bardzo dobra. Początkowo obawiałem się, że podczas pisania pojawią się takie rzeczy, których nie będę umiał zrobić. Nie należy się tego obawiać. W edytorach typu Microsoft Word, jeśli nie umiesz czegoś zrobić, to często nawet nie wiadomo jakie zapytanie wpisać do wyszukiwarki, aby rozwiązać problem. W LaTeX’u tak naprawdę jest dużo łatwiej. W każdym przypadku, zawsze, szybciej lub później udawało mi się znaleźć potrzebną do rozwiązania komendę.
Innym częstym problemem jest strona tytułowa, której układ sformalizowany dla danej uczelni może być kłopotliwy do samodzielnego uzyskania. Polecam w tym przypadku poszukać gotowych szablonów, najlepiej wśród studentów uczelni. Mniej obeznany użytkownik LaTeX’a faktycznie może mieć problemy z samodzielnym wytworzeniem stron tytułowych. Przed zabraniem się do poważniejszej pracy polecam również metodę polegającą na przećwiczeniu sobie najpotrzebniejszych zadań oraz komend potrzebnych do ich zrealizowania np. tabelki, bibliografii, wypunktowania etc. Z takich ćwiczeń warto jest utworzyć sobie jeden dokument zawierający przykłady użycia komend. We właściwej pracy można wtedy posiłkować się taką ściągawką i całkowicie skupić się ma zawartości merytorycznej tekstu.
Czy LaTeX ma jakieś wady? Aby opanować LaTeX’a należy się trochę wysilić. Opanowanie całości jest raczej niemożliwe i z pewnością bardzo trudne. Osobiście uważam, że słabo znam LaTeX’a. Ciekawe jest jednak to, iż znając nawet stosunkowo niewielki podzbiór komend można już zacząć wydajnie pracować. Inną wadą może być proces dostrajania różnych drobiazgów. Czasami bywa tak, że z pewnymi komendami trzeba eksperymentować, wielokrotnie kompilować dokument i patrzeć, czy rezultat jest właściwy. W pewnych przypadkach może to być uciążliwe, ale de facto jest to częścią procesu uczenia się LaTeX’a. Jeżeli natrafimy na dobre wytłumaczenie danej komendy wraz z przykładem to, można tego uniknąć.
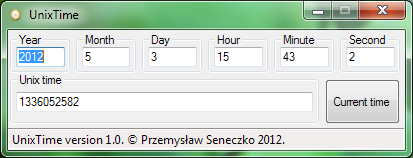
W codziennej pracy bardzo często mam do czynienia ze znacznikiem czasowym typu Unix. Konwersja pomiędzy, nazwijmy to, “naturalnym” formatem czasu, a liczbą sekund, która upłynęła od 1 stycznia 1970 roku jest stosunkowo prosta. Jednakże moja praktyka pokazuje, że również niewygodna. Środowisko baz danych, z którym pracuję nie udostępnia stosownych funkcji w każdym schemacie, co prowadzi do kłopotliwego “zgadywania” gdzie znajduje się definicja funkcji. Z kolei napisane proste skrypty shell’owe opakowujące wywołania funkcji konwertujących Perl’a wymagają, jak nietrudno się domyślić, powłoki systemu Unix, co w systemie Windows również nie jest zbyt wygodne.
Zaistniała potrzeba stworzenia narzędzia z graficznym interfejsem, działającego w systemie Windows, takiego, które pozwoli na błyskawiczną konwersję zapisanego czasu w obie strony, bez zbędnego zastanawiania się w jakiej kolejności podać “naturalne” części daty. Napisałem w tym celu bardzo prosty program, który ma następujące właściwości:
Konwersja czasu do i z formatu systemu Unix “w locie”, tzn. podczas pisania.
Automatyczne zmiana fokusu na kolejne pole, po wpisaniu 4-cyfrowego roku, oraz kolejnych 2-cyfrowych fragmentów.
Możliwość ręcznego przełączania kolejnych pól za pomocą klawisza TAB.
Automatyczne wyświetlanie bieżącego czasu po uruchomieniu programu, oraz możliwość ręcznej aktualizacji do bieżącego czasu.
Należy pamiętać, że czas w formacie Unix liczony jest według czasu UTC. W związku z tym, data podawana w górnej części interfejsu mojego programu przed przeliczeniem na timestamp jest najpierw przeliczana na czas UTC według ustawień strefy czasowej systemu (dla Polski +1 godzina, w związku z tym program odejmuje 1 godzinę od podanego czasu).
Program do poprawnego działania potrzebuje środowiska .NET w wersji 2.0, co w praktyce pozwala założyć, iż będzie działał w każdym współczesnym systemie Windows. Możliwe jest dowolne, darmowe wykorzystanie i rozpowszechnianie jego skompilowanego pliku wykonywalnego. Poniżej link do pobrania:
UnixTime.zip
Oprogramowanie o otwartym kodzie źródłowym, jak by się mogło wydawać, budzi ogromny entuzjazm zarówno wśród programistów, jak i użytkowników. Programiści przykładowo mają możliwość korzystania z potencjału drzemiącego w ogólnodostępnym dla wszystkich kodzie źródłowym. W przypadku zaś darmowych narzędzi i bibliotek – w znaczący sposób zmniejszają one koszty wytwarzania oprogramowania. Jakby tego było mało, można liczyć na pomoc przyjaźnie nastawionej społeczności innych entuzjastów, która gotowa jest pomóc nawet w najcięższych przypadkach. Jak by się mogło wydawać, również użytkownicy oprogramowania o otwartym kodzie źródłowym powinni być wielce usatysfakcjonowani, ponieważ nie dość, że mają produkt za darmo, to jeszcze mają świadomość, iż został on stworzony przez prawdziwych specjalistów, pracujących nad rozwojem programu “z potrzeby serca”.
Niestety, jak to w życiu bywa, pozory mylą i powyższy obraz jest czysto teoretyczny. Nie będę omawiać wątpliwości dot. aspektów użytkowych oprogramowania open-source, ponieważ jest to temat na oddzielny post. Chciałbym skupić się na zagadnieniach istotnych z punktu widzenia programisty oraz podać konkretny przykład, który mnie osobiście zabolał.
W ostatnim czasie spotkałem się z opinią zawodowego programisty, iż korzystanie z rozwiązań open-source w poważnym komercyjnym projekcie może być ryzykowne, kosztowne, a nawet szkodliwe. Uzasadniając swoje zdanie, programista ten przedstawił kilka konkretnych zarzutów:
Nikt osobiście nie bierze odpowiedzialności za zagwarantowanie rozwoju, uaktualnień oraz wsparcia dla rozwiązań open-source. Podany został przykład sytuacji, gdy w pracach nad komercyjnym projektem szeroko wykorzystywano darmową bibliotekę. W pewnym momencie wydana została nowa wersja biblioteki, całkowicie niekompatybilna z poprzednią. Autor biblioteki całkowicie “odciął” się od starej wersji i zaprzestał jej utrzymywania. Zespół stanął przed dramatycznym wyborem: korzystać ze starej wersji narażając się na wszelkie kłopoty z tym związane, czy całkowicie przepisać projekt, tak by korzystał z nowej wersji. Wybrano to drugie rozwiązanie, co z punktu widzenia rozwoju stanowiło półroczny przestój.
Wsparcie społeczności również nie jest czymś, co może być w jakikolwiek sposób zagwarantowane. Czasami bywa też tak, że projekt “umiera” i nikt, z autorem włącznie, już się nim nie interesuje. Wtedy nawet nie wiadomo do kogo zwrócić się w przypadku problemów.
Otwarty kod źródłowy wcale nie oznacza szybszego reagowania na błędy. Znane są przypadki, gdy autorzy całkowicie ignorowali błędy znajdowane przez użytkowników. Programiści musieli poprawiać znaleziony przez nich samych błąd w bibliotece samodzielnie kompilując każdą kolejną jej wersję, tak aby nadawała się do użytku w ich projekcie. Skutkiem tego było to, iż zespół przeznaczony do prac nad projektem de facto pracował nad dwoma projektami: właściwym projektem + biblioteką, która była im potrzebna.
Dokumentacja w przypadku open-source to jest coś, co może istnieć, ale wcale nie musi.
Opublikowany przez autora kod źródłowy może być w postaci kompletnie nieutrzymywalnej. I na przykład może się wcale nie kompilować. Takie przypadki też istnieją.
Wyżej wymieniłem najważniejsze, potencjalne problemy, jakie można na siebie sprowadzić korzystając z rozwiązań open-source. Oczywiście nie należy generalizować i postrzegać wszystkich rozwiązań przez pryzmat tego typu kłopotów. Niemniej jednak zamiast entuzjastycznie skakać z radości, warto mieć świadomość ryzyka.
Osobiście boleśnie doświadczyłem pierwszego i czwartego z opisywanych problemów. W ramach pracy magisterskiej tworzyłem proste narzędzie do symulacji błędów działające w trybie jądra systemu Linux. Nie wnikając za bardzo w szczegóły, jest to rozwiązanie zbliżone koncepcyjnie do klasycznych debugger’ów, jednakże zamiast wykorzystywać API systemu operacyjnego (kwestie wydajnościowe w przypadku narzędzi programowej symulacji błędów) implementuje własne mechanizmy modyfikujące procedury obsługi przerwań poprzez patch’owanie kodu jądra “w locie”. Bazowym mechanizmem w tym rozwiązaniu jest ustawianie brakpoint’ów sprzętowych. Jądro udostępnia do tego celu elegancką funkcję register_user_hw_breakpoint. Super. Tylko, że ta funkcja, choć należy do API jądra od wersji 2.6.33 jest nieudokumentowana. Próżno szukać jej opisu na stronie dedykowanej API na kernel.org/doc. Jedynym dokumentem jest chyba artykuł z Linux Symposium dostępny w wielu miejscach w internecie (m.in. http://kernel.org/doc/ols/2009/ols2009-pages-149-158.pdf), który stanowi wstęp koncepcyjny autorstwa deweloperów odpowiedzialnych za implementację mechanizmu.
Aby funkcja utworzyła breakpoint sprzętowy na instrukcji wykonywalnej, jako wielkość należało jej podać stałą HW_BREAKPOINT_LEN_1. Tak było w wersjach jądra od 2.6.33 do 2.6.35. Problem zaczął się, gdy przetestowałem swój program na nowszych wersjach. Funkcja po prostu przestała działać. Nigdzie nie udało mi się znaleźć żadnych informacji, czy, jak i dlaczego interfejs uległ zmianie. Co gorsze, nigdzie w jądrze nie było wywołań tej funkcji z takim zestawem parametrów, jakiego używałem ja. Nie było więc niczego, na czym można by się wzorować. Przyznam, że straciłem sporo czasu analizując kod jądra w poszukiwaniu jakichkolwiek wskazówek, co mogło się stać. Miałem szczęście. Znalazłem. Okazuje się, że od wersji jądra 2.6.36 w przypadku pułapek sprzętowych, rozmiar musi być ustawiony jako sizeof(long), a nie jako wartość ww. stałej. Świetnie. Taka mała, ale niesamowicie złośliwa, nieudokumentowana, funkcjonalna zmiana w interfejsie API. Chyba jedna z gorszych rzeczy, jakie mogą spotkać programistę. Ale ja i tak miałem szczęście, moje rozwiązanie jest stosunkowo proste. Wywoływałem tę funkcję tylko 2 razy. Aż boję się pomyśleć co by było, gdyby coś takiego zdarzyło się podczas rozwoju naprawdę dużego projektu.
Zwolennicy open-source oraz członkowie społeczności deweloperów jądra mogą w tym miejscu zarzucić mi, że jestem amatorem, bo modyfikacja ta na pewno gdzieś jest opisana w jakimś commicie do repozytorium kodu jądra. A poza tym, to sam sobie jestem winien, bo interfejs programistyczny jądra jawnie nie gwarantuje kompatybilności pomiędzy różnymi wersjami jądra zarówno na poziomie funkcji jak i ABI. Owszem, wiem o tym. Tylko, czy to przypadkiem nie jest kolejne potwierdzenie, że stosowanie rozwiązań open-source może (oczywiście nie musi) wiązać się z dodatkowymi, nieprzewidywalnymi kłopotami?
Spotkałem się wielokrotnie z narzekaniami użytkowników systemu Windows, że po zastosowaniu hibernacji ich system zaczyna działać bardzo wolno i praktycznie nie nadaje się do użytku. Użytkownicy ci twierdzą, że problemy te są tak dokuczliwe, że nie korzystają z hibernacji w ogóle. W dzisiejszym wpisie chciałbym spojrzeć od strony technicznej na możliwe przyczyny takiego stanu rzeczy i zasugerować sposoby jeśli nie całkowitego, to przynajmniej częściowego zwalczenia problemu.
Na początku zwrócę również uwagę, że zdumiewająco mało osób korzysta z hibernacji i / lub usypiania komputera. Osobiście nie wyobrażam sobie życia bez tych dwóch opcji i nigdy (poza historyczną już wersją systemu Windows 2000, gdzie mechanizm hibernacji nie działał prawidłowo na wielu komputerach) nie doświadczyłem żadnych problemów z nimi związanych. Z użytkowego punktu widzenia często, gdy pracuję z użyciem kilkunastu aplikacji na raz, mając otwartych wiele różnych plików, to nie wyobrażam sobie codziennego uruchamiania i otwierania tego wszystkiego. Osobiście prawie nigdy nie wyłączam komputera zamykając jednocześnie system. Najczęściej usypiam komputer, w przypadku notebooka i odłączeniu go od zasilania zapewnia mu możliwość wykorzystywania akumulatorów, co jest dla nich dodatkowo korzystne. Gdy z jakichś przyczyn nie mogę uśpić komputera (akumulator jest zepsuty), a nie ma sensu usypiać laptopa podłączonego do prądu, wtedy używam hibernacji. Efekt końcowy jest w zasadzie identyczny.
W zasadzie, ponieważ, jak twierdzą niektórzy użytkownicy, po odhibernowaniu komputer zaczyna działać bardzo wolno. Kluczem do zrozumienia, dlaczego faktycznie komputer ma prawo zacząć działać wolno jest uświadomienie sobie pewnych specyficznych mechanizmów zarządzania pamięcią we współczesnych systemach operacyjnych, których działanie nie jest intuicyjne.
Hibernacja polega na zapisaniu zawartość używanej części pamięci fizycznej na dysk i wyłączeniu komputera. Wbrew pewnym opiniom, które napotkać można w Internecie, hibernacja z punktu widzenia sprzętowego powoduje takie samo wyłączenie komputera, jak opcja zamykania systemu. To system operacyjny jest odpowiedzialny za zrealizowanie całej operacji. Podczas normalnego działania systemu operacyjnego tylko część zarezerwowanej przez programy pamięci jest faktycznie zajmowana w pamięci fizycznej. Pozostała, ta mniej używana część jest przenoszona do pliku wymiany, na dysk twardy. W razie potrzeby, rzadziej używane fragmenty pamięci są “sprowadzane” z powrotem do pamięci fizycznej. Mechanizm ten nazywa się stronicowaniem na żądanie i pozwala na zoptymalizowane wykorzystanie pamięci fizycznej. Oprócz tego, gdy system operacyjny działa przez dłuższy czas, w pamięci fizycznej znajdują się nie tylko uruchomione programy, ale również bufor (ang. cache) operacji dyskowych. Bufor ten jest częścią pamięci fizycznej używanej przez system (ang. system working set) i podczas hibernacji jest zapisywany na dysk. Pamięć, która podawana jest w systemowym menedżerze zadań jako wolna w rzeczywistości też jest używana przez system. Jest tam tzw. standby list. Gdy system decyduje o przeniesieniu nieużywanej pamięci do pliku wymiany, owszem oznacza ją jako nieużywaną, ale zachowuje jej zawartość, tak na wszelki wypadek, gdyby trzeba było z niej szybko skorzystać (bo skorzystać można i tak, tylko, że sprowadzenie tego obszaru z pliku wymiany jest czasochłonne). Zarządzanie systemem buforowania w Windows wykonywane jest przy użyciu tego samego mechanizmu, który zarządza pamięcią. W związku z tym, część zawartości bufora plików, która przestaje być używana, również przenoszona jest do standby list, tak na wszelki wypadek, gdyby w przyszłości była potrzebna.
Gdy system działa przez dłuższy czas, standby list zapełnia prawie całą nieużywaną pamięć fizyczną, powodując, że wszystkie dane, które potencjalnie mogą być w każdej chwili potrzebne są obecne w pamięci fizycznej, do której dostęp jest bardzo szybki. Po długim działaniu komputera, mając uruchomione cały czas te same programy i wykonując takie same operacje, standby list w “inteligentny” sposób zapełnia pamięć komputera powodując płynne i szybkie działanie uruchomionych programów.
W tym momencie zbliżamy się do wyjaśnienia zagadki powolnego działania po odhibernowaniu. Przy hibernacji zapisywana jest tylko pamięć używana przez programy, czyli ta, która jest raportowana przez system jako faktycznie zajęta. Standby list nie jest zapisywana. Odhibernowany system musi ponownie załadować z dysku dane, które były zbuforowane w nieużywanej części pamięci. Nie ma możliwości wpłynięcia na zawartość standby list, więc w tym temacie niczego nie da się zmienić. Ale jest jeszcze jedno spostrzeżenie: gdy raportowane przez system zużycie pamięci jest duże, to zapewne plik wymiany również jest w znacznym stopniu wykorzystywany. Przed zahibernowaniem, jak wspomniałem, część danych przeniesionych na dysk do pliku wymiany znajduje się jeszcze w pamięci w standby list. Po zahibernowaniu i odhibernowaniu, wszystkie żądania sprawdzenia nieużywanych obszarów pamięci z pliku wymiany będą również skutkowały faktyczną operacją dyskową odczytu, co jest czasochłonne z punktu widzenia wykonywania programów. Jest to powód spowolnionego działania komputera po odhibernowaniu.
W jaki sposób tego uniknąć? Osobiście staram się nie hibernować systemu z bardzo dużym zużyciem pamięci. Dzięki temu przynajmniej częściowo eliminuję narzut czasowy potrzebny na sprowadzenie z pliku wymiany potrzebnych obszarów pamięci. Trudno podać mi konkretne liczbowe zalecenia, ale z moich doświadczeń wynika, że hibernowanie przy zużyciu pamięci mniejszym niż 50% nie powinno sprawiać absolutnie żadnych problemów po odhibernowaniu. Przed zahibernowaniem polecam więc użycie menedżera zadań, wybranie kilku najbardziej pamięciożernych aplikacji i zamknięcie ich. Najlepszymi, uniwersalnymi kandydatami na sam początek są przeglądarki internetowe, programy pocztowe i komunikatory. U mnie to działa.
PS. Problemy te nie dotyczą usypiania komputera, ponieważ wtedy zawartość pamięci fizycznej jest zachowywana (pamięć jest wtedy jedyną częścią komputera, która pozostaje zasilana).