W związku z nadchodzącymi dość dużymi zmianami w portalu społecznościom Facebook, chciałbym zwrócić uwagę na pewien negatywny aspekt tych “nowości” związany z kolejnym ograniczaniem prywatności. Zacznijmy od rzeczowego podsumowania, o co w ogóle chodzi - artykuł w serwisie Mashable.com:
Oraz wątpliwej kwestii ciasteczek przechowywanych przez serwis nawet po wylogowaniu się - artykuł w serwisie MakeUseOf.com:
Krótko mówiąc, chodzi o to, że:
Rewelacje właśnie wprowadzane przez Facebook, mogą spowodować, że jeśli użytkownik nie ogarnia w 100% tego jak działają i jaki skutek mają opcje ustawione w jego profilu, to może dojść do sytuacji, że jego profil będzie rozgłaszał bez jego świadomości informacje o tym, jakie przegląda on strony internetowe
Facebook przechowuje pewne informacje o użytkowniku, w postaci ciasteczka - pliku tekstowego zapisanego w przeglądarce - nawet po jego wylogowaniu się z serwisu. Oficjalne wyjaśnienia, a jakże by inaczej, zapewniają użytkowników, że to dla ich dobra. Ale nie sposób oprzeć się konkluzji, że informacje te mogą być wykorzystywane na jeszcze inne sposoby, np. przez wszelkie rewelacyjne, ostatnio modne wtyczki na przeróżnych stronach integrujące się z Facebook’iem
W czerwcu 2010 roku opublikowałem post w którym wyjaśniam moje podejście do kwestii związanych z bezpieczeństwem przeglądania stron internetowych. Wiele osób zarzucało mi wtedy, że jestem paranoikiem i przesadzam używając na co dzień dwóch przeglądarek internetowych. W kontekście opisanych wyżej “nowości”, albo raczej potencjalnych kłopotów, mój pomysł odizolowania zwykłego przeglądania stron internetowych od bycia zalogowanym w wszelkiego rodzaju serwisach wydaje się jeszcze bardziej uzasadniony. Mówiąc wprost, przy zastosowaniu moich pomysłów te problemy w ogóle nie istnieją. Facebook w żaden sposób nie dowie się, co robię na innych stronach, bo robię to w innej przeglądarce.
Ponieważ wspomniany post jest napisany językiem technicznym, krótko opiszę raz jeszcze co jest istotą mojego pomysłu:
Zainstalowanie drugiej przeglądarki internetowej, której używa się tylko do logowania w serwisach takich jak np. Google Gmail, Facebook itd.
Nie można mieć uruchomionych dwóch przeglądarek obok siebie. Nowo otwierane okna należą do tej samej instancji programu. Potrzebny jest oddzielny program. Osobiście używam przeglądarki Seamonkey, ponieważ moją główną przeglądarką jest Firefox. Ale nic nie stoi na przeszkodzie, żeby były to inne kombinacje np. Firefox i Opera, Firefox i Internex Explorer albo najciekawsze: Firefox i Firefox — tak jest to możliwe. Istnieje program o nazwie Palemoon, który jest po prostu Firefox’em tylko, że skompilowanym specjalnie dla nowoczesnych komputerów. Ale jest oddzielnym programem, który może być uruchomiony obok zwykłego Firefox’a
Istotne jest ustawienie w obu przeglądarkach czyszczenia ciasteczek po zamknięciu programu. Tak naprawdę ciężko mi jest uzasadnić sens przechowywania ciasteczek, poza wyjątkowymi przypadkami gdy np. ktoś gra w jakieś gry online, które w ten sposób zapisują wyniki. W większości przypadków utracimy jedynie możliwość logowania bez podawania hasła w niektórych stronach, która i tak jest niebezpieczna. Z resztą to można obejść zapamiętując swoje hasło w menedżerze haseł - wychodzi na to samo. Co zyskujemy? Duże utrudnienie w identyfikowaniu nas i zbieraniu informacji o nas. Takie np. Google wyświetla inne wyniki wyszukiwania gdy pozbiera trochę informacji o tym gdzie klika użytkownik. Bardzo nie lubię sytuacji gdy komputer wie lepiej co jest dla mnie dobre, wolę za każdym razem mieć “czyste” wyniki wyszukiwania i jawić się wyszukiwarce za każdym razem jako “świeży” użytkownik
Istotna jest aktualność używanych przeglądarek, o którą należy dbać
Życzę szybkiego zorientowania się jak działają Facebook’owe “rewelacje” 
Chciałbym przedstawić zdumiewające zagadnienie dotyczące obsługi bluetooth w tablecie Creative ZiiO 7. Co prawda jest to urządzenie z dolnej półki jeśli chodzi o tablety, niemniej jednak w mojej ocenie jest całkiem funkcjonalne. Niestety okazało się, że niektóre funkcjonalności są rozumiane przez producenta w nieco odmienny sposób niż mogłoby się to wydawać.
Problem dotyczy przesyłania plików z komputera do urządzenia poprzez bluetooth. Mówiąc krótko nie da się. Wysyłanie plików w systemie Windows kończy się błędem. Rzecz jasna, urządzenia są sparowane i “widzą się”. Co ciekawe, smartfon Nokia potrafi wysłać pliki do tabletu ZiiO bez żadnych problemów. Wystosowałem w tej sprawie następujące zapytanie do obsługi klienta firmy Creative:
I have a problem when connecting the device with 64-bit Windows 7 PC via bluetooth. The computer cannot send files to ZiiO. The configuration of computer OS is absolutely correct because it can clearly send files via bluetooth to Nokia smarphone. Furthermore, the Nokia smartphone can send files to the ZiiO, so it prooves that ZiiO is also properly configured. It seems that there is some issue with Microsoft bluetooth stack (i use default Windows tools to send files via bluetooth) and Android
Odpowiedź, którą otrzymałem jest jak następuje (podkreślenia moje):
May I know what file type have you transferred from your Nokia Smartphone to your ZiiO unit?
Was it transferred just by pairing the devices via bluetooth?
Please take note that the bluetooth feature of the ZiiO tablet is meant for streaming high fidelity stereo wirelessly to all compatible stereo Bluetooth speakers and headphones such as the ZiiSound D5, ZiiSound T6 and Creative WP-300 Headphones. It was never meant for file transferring.
Czy firma Creative jest w porządku? Formalnie tak, na jej stronie widnieje następujący opis feature’a tabletu związanego z bluetooth:
Bez przewodów, bez problemów - tylko nieskazitelna muzyka odtwarzana poprzez Bluetooth Dzięki wykorzystaniu technologii Bluetooth oraz apt-X urządzenie ZiiO 7” zapewnia wysoką wierność muzyki odtwarzanej bezprzewodowo. Urządzenie to może współpracować ze stereofonicznymi głośnikami Bluetooth - takimi jak głośniki Creative ZiiSound D5 oraz ZiiSound T6 - a także stereofonicznymi słuchawkami Creative WP-300.
(źródło: http://pl.store.creative.com/urzadzenia-multimedialne-odtwarzacze-mp3/ziio-7/948-20231.aspx)
Nie znam się na szczegółach technicznych implementacji stosu bluetooth. Niemniej jednak uwagę zwraca puste okienko usług dostępnych na sparowanym z komputerem tablecie:
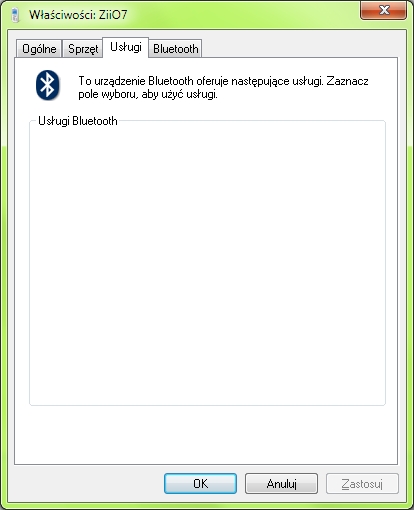
Poniżej lista usług smartfonu:
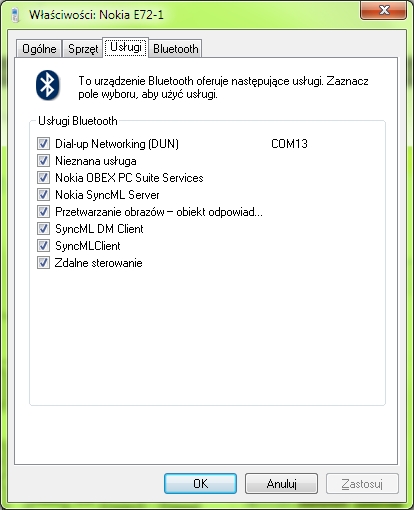
ZiiO jest tabletem pracującym pod kontrolą systemu Android w wersji 2.2. Funkcjonalność przesyłu plików przez bluetooth jest na standardowym wyposażeniu tego systemu, idę o zakład, że potrafi to każdy telefon z tym systemem. Wygląda na to, że firma Creative celowo zmodyfikowała implementację stosu bluetooth systemu Android tak, aby urządzenie nie obsługiwało żadnych usług bluetooth poza ich własną polegającą na jakimś niby cudownym przesyłaniu dźwięku.
Zagadnienie działającego przesyłu w kierunku smartfon Nokia -> tablet nie jest dla mnie do końca jasne. Być może implementacja stosu bluetooth w systemie Symbian jest tak skonstruowana, że rozpoczyna przesył pliku, nawet jeśli docelowe urządzenie nie “chwali się” tym, jakie usługi są na nim dostępne.
Chciałbym pogratulować z tego miejsca pomysłowości producentowi. Nie ma to jak zmodyfikować implementację technologii, która ma dziesiątki zastosowań tak, aby nadawała się tylko do jednego z tych zastosowań. Moim zdaniem producent powinien pójść w dokładnie przeciwnym kierunku i wręcz rozszerzyć obsługę bluetooth np. o dial-up networking, co umożliwiłoby podłączenie urządzenia do internetu poprzez dowolny telefon komórkowy. AFAIK nie jest to możliwe w systemie Android w wersji 2.2, natomiast coś takiego potrafi (co prawda po zainstalowaniu dodatkowego oprogramowania) konkurencja spod znaku jabłka – iPad. Oczywiście nie mam zamiaru załamywać się z powodu problemów z transferem, ponieważ istnieją rewelacyjne programy takie jak WiFi File Explorer, które umożliwiają przesyłanie plików szybciej i łatwiej niż przez bluetooth, niemniej jednak chciałbym zwrócić uwagę na niepokojący trend we współczesnej elektronice użytkowej polegający na tym, że producenci w coraz bardziej drastyczny sposób zaczynają ograniczać to, jak klient może używać ich produktu.
PS. Nie czuję się aż tak bardzo poszkodowany. Podobno konkurencja spod znaku jabłka też nie potrafi przesyłać plików przez bluetooth.
Czytam sobie dzisiaj newsy z serwisu OSnews.pl i widzę takie coś:
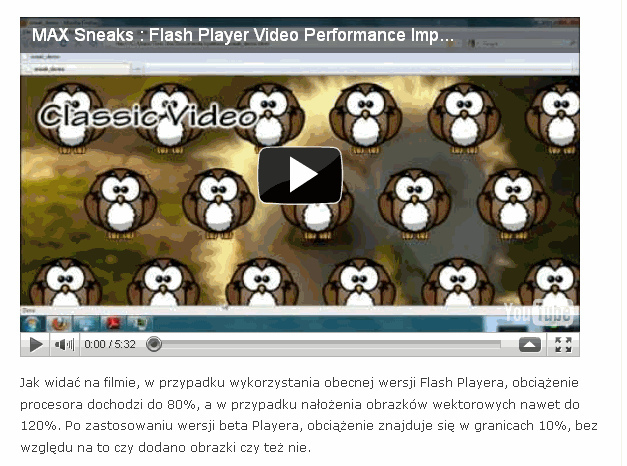
O niskim poziomie większości polskich mediów wiem nie od dziś, ale od dziś chyba zacznę ograniczać listę serwisów internetowych z branży IT, które stanowią dla mnie źródło bieżących informacji. Do niektórych mam już poważne wątpliwości. Zastanawiam się, komu przyszło do głowy “120% czasu procesora”. Nie sądzę, żeby tego typu informacje były podawane przez firmę Adobe, podejrzewam, że jest to dziennikarska interpretacja. Moim zdaniem niedorzeczna. Chyba, że pojawiły się jakieś nowe jednostki czasu, tudzież nowa definicja procenta, o której nie wiem. Jeśli tak, bardzo proszę oświecić mnie w komentarzach.
Jak można poświęcać 120% czasu na coś? Czy jeśli pracuję 8 godzin dziennie, mogę powiedzieć, że jakieś zadanie wykonywałem przez 120% mojego czasu pracy? Czyli wykonywałem je przez 9,6 godziny. Ale przecież pracuję 8 godzin, czyli nie mogłem pracować 9,6 godziny. dochodzimy do sprzeczności. Czy dla kogoś doba ma więcej niż 24 godziny?Może ta różnica to właśnie te procenty ponad 100 ;) ? W informatyce, o ile wiem, czas liczy się w ten sam sposób jak w każdej innej dziedzinie. Współcześnie używane w większości komputerów systemy operacyjne to tzw. systemy z podziałem czasu. System operacyjny wyznacza pewne krótkie okresy, rzędu milisekund, które przydziela procesom (proces to program podczas działania) na to, by mogły być wykonywane przez procesor. Gdy procesor “nudzi się”, to jest, gdy wszystkie procesy wykorzystały swoje kwanty, aby zrobić to, co miały do zrobienia, system przydziela do wykonywania na procesorze tzw. proces bezczynności, który “wykonuje nic nie robienie” (w pewnym uproszczeniu). Fachowo nazywa się to instrukcja NOP - no operation. Zajętość procesora oznacza tak naprawdę ile czasu zajmowało nic nie robienie w stosunku do wykonywania procesów. Zajętość nigdy nie może wynosić 0, ponieważ cały czas wykonywany jest kod samego systemu operacyjnego, który chociażby zarządza wspomnianym przydzielaniem czasu. Zajętość może wynosić 100%, taka sytuacja ma miejsce wtedy, gdy jest dużo procesów, które intensywnie pracują i procesor nie spędził nawet ułamka chwili na nic nie robieniu. W takiej sytuacji krytycznym zadaniem systemu operacyjnego jest sprawiedliwy podział czasu, tak, aby wszystkie procesy dostały chociaż na króciutką chwilę szansę wykonania na procesorze i żeby żaden z nich nie “zawłaszczył” sobie całego czasu procesora blokując na przykład sam system operacyjny, który tym wszystkim zarządza. To jak zrealizować tę sprawiedliwość jest opisane w wielu opasłych księgach na temat teorii konstrukcji systemów operacyjnych, z których osobiście polecam Abraham Silberschatz “Podstawy systemów operacyjnych”. Mając takie wyobrażenie o działaniu komputera naprawdę trudno mi jest wyobrazić sobie, co może oznaczać powyższe 120% czasu. Utwierdza mnie to tylko w przekonaniu, że w tematyce związanej z komputerami jest coraz więcej pseudo-fachowców, którzy de facto nie mają pojęcia, o czym mówią.
Aktualizacja - 23.01.2011
W międzyczasie spotkałem się wyżej opisaną konwencją podawania wskaźnika użycia procesora. Okazuje się, że przyjmuje ona jako 100% pojedynczy procesor (rdzeń), więc gdy w systemie jest ich więcej, wynik może przekroczyć 100% w przypadku aplikacji które wykonują intensywne obliczenia wykorzystując wiele wątków/procesów. Konwencja ta jest używana np. przez Unix’owe narzędzie time. Poniżej przedstawiam wynik działania time’a dla specjalnego narzędzia zrównoleglającego wykonywanie skryptów: ppss.
$ /usr/bin/time ppss -d /opt/Adobe -c 'tar -cvjf ./adobe.tar.bz'
255.25user 440.59system 7:05.44elapsed 163%CPU (0avgtext+0avgdata 0maxresident)k
2992inputs+6384outputs (20major+9669583minor)pagefaults 0swaps
Tak więc moje zarzuty o bezsensowności okazały się trochę przedwczesne. Pierwszą część tego wpisu jednakże pozostawiam w niezmienionej postaci, ponieważ i tak uważam, że konwencja ta jest myląca, a oprócz tego ktoś z czytelników może mieć podobne spostrzeżenia i wątpliwości do moich, gdy zobaczy liczbę większą od 100%.
Z przygotowanego przeze mnie rozwiązania skorzystają zapewne tylko użytkownicy tego całkiem dobrego sprzętu do czytania ebook’ów. Jednakże, aby zachować wartość merytoryczną tego wpisu dla wszystkich czytelników, w drugiej części opisuję swoje spostrzeżenia i uwagi dotyczące tworzenia skryptów wiersza poleceń w systemie Windows.

2. Problemy przy rozwiązywaniu problemu, czyli pisanie skryptu wiersza poleceń
Gdy w różnych pseudo-fachowych poradnikach spotyka się porównania systemu Windows do systemu Linux to bardzo często zawarte są tam stereotypowe stwierdzenia, że w systemie Windows wiersz poleceń jest bezużyteczny, zaś w systemie Linux ma ogromne możliwości. W takich sytuacjach nie mogę oprzeć się refleksji, że autorzy takich porównań po pierwsze chyba nigdy sami nie napisali żadnego skryptu, a po drugie pewnie nie słyszeli, że od paru lat Windows ma Powershell, który jest de facto bardzo potężną powłoką. Poniżej postaram się pokazać kilka argumentów za tym, że standardowy interpreter poleceń systemu Windows jest jednak użyteczny, aczkolwiek ciężko.

2.1 Zapisywanie wyniku działania polecenia do zmiennej
Przykładowy przypadek użycia: wiemy, że w katalogu znajduje się plik wykonywalny (z rozszerzeniem .exe), ale nie wiemy jak się nazywa.
Kod cmd:
for /f %i in ('dir *.exe /b') do @set x=%i
echo %x%
Kod sh:
x=`ls *.exe`
echo $x
Jest to dziwactwo straszliwe: aby zapisać wynik do zmiennej trzeba. użyć pętli for. Koniecznie z przełącznikiem /f, który to umożliwia. Problem pojawia się, gdy wynik polecenia jest wielowierszowy. Przyznam, że nie zastanawiałem się nad tym, ale pewnie trzeba jeszcze bardziej kombinować. W powłoce Unix’a rzecz prosta i oczywista, bez żadnych dodatkowych komplikacji.
2.2 Różnice w semantyce poleceń
W cmd jest polecenie ren, które służy do zmiany nazwy pliku. W sh jest polecenie mv, które służy do przenoszenia plików, a w szczególności do zmiany ich nazwy. W sh w poleceniu mv możemy podać pełne ścieżki do plików. W ren ścieżkę podajemy tylko do pierwszego argumentu, drugi - czyli nowa nazwa musi być bez ścieżki. Żeby było ciekawiej w cmd jest też polecenie move, które działa tak samo jak mv z sh. Niby mało istotny szczegół, ale może spowodować nieoczekiwane wykolejenie się skryptu.
2.3 Liczenie w skrypcie
Przykładowy przypadek użycia: tworzenie zmiennych nazw plików w skrypcie.
Kod cmd:
set a=0
set /a a+=1
Kod sh:
a=0
a=`expr $a + 1`
Jak widać w cmd można liczyć. Polecenie set zostało unowocześnione i obsługuje teraz wyrażenia. Aczkolwiek, gdy ktoś tego nie wie i zabiera się za pisanie skryptu to jest mała szansa, że wpadnie na to, że trzeba użyć akurat polecenia set. Moim zdaniem język powłoki unixowej znów jest bardziej czytelny, prosty i logiczny. Używamy podstawowego mechanizmu: znaków akcentu i specjalnego polecenia, które służy do liczenia.
2.4 Podstawianie wartości zmiennych przez interpreter
Przykładowy przypadek użycia: wykorzystywanie w pętli for wartości pewnej zmiennej oraz modyfikacja tej wartości.
Kod cmd:
set a=0
for %s in (.\fixed_ebook\*.html) do (
set /a a+=1
echo %a%
)
Świetnie. Tylko, że ten kod nie działa. Trochę czasu i nerwów straciłem zanim dotarłem do wytłumaczenia zawartego w pomocy do polecenia set. Otóż interpreter cmd podstawia wartość zmiennej w momencie wczytywania linii z poleceniem, a nie jej wykonania. Wczytuje polecenie for, podstawia wartość zmiennej a i wykonuje. Dzięki temu wyświetlone zostaną same zera. Okazuje się, że trzeba użyć specjalnego dodatkowego polecenia, które “sprowadza interpreter na ziemię” i powoduje normalne (w sensie powłoki Unix’a) podstawianie wartości (trzeba jednak użyć znaków ! zamiast %).

W sh oczywiście takich niuansów nie ma, a pętlę for można nawet zapisać sobie w jednej linii, bo koniec poleceń oznacza się średnikiem (brakuje mi tego w cmd). Niemniej jednak ten prosty w świecie Unix’a chwyt z liczeniem jest również możliwy w systemie Windows.
Na koniec zwrócę jeszcze uwagę, że w przypadku wykonywania pętli for w skrypcie, trzeba użyć dwóch znaków % przy zmiennej. W przypadku wpisywania ręcznie w interpreterze trzeba użyć jednej. Niuans ten, jak i powyższe spostrzeżenia moim zdaniem wystarczają do tego, żeby stwierdzić, że pisanie skryptów w cmd jest męczące. Pominąłem tutaj zupełnie wspomniany na początku PowerShell, gdyż jest to całkiem inny język i niekoniecznie jest obsługiwany przez starsze wersje systemu Windows (w XP trzeba go doinstalować).
W przypadku gdy Windows ulegnie awarii i wiadomo, że przyczyną jest sterownik lub usługa to można posłużyć się narzędziami z płyty instalacyjnej dowolnego z systemów nowszych od XP (Vista, 7, Server 2008), aby wyłączyć problematyczny komponent. Piszę o tym dlatego, że jest to sztuczka niekoniecznie oczywista, ponieważ domyślnie instalator wyszukuje kompatybilne instalacje systemu na dysku i proponuje czynności typu przywracanie stanu systemu bądź przywracanie obrazu partycji (kompatybilne w tym sensie, że aby zastosować je na konkretnej wersji systemu, to trzeba użyć płyty instalacyjnej właśnie tej wersji. Przykładowo nie można przywrócić stanu systemu w wersji XP z płyty instalacyjnej wersji 7). Po wybraniu opcji naprawy systemu w instalatorze i ewentualnym zignorowaniu komunikatów o niewykryciu instalacji systemu ani obrazów, uzyskujemy dostęp do opcji uruchamiającej wiersz poleceń. I to jest właśnie najważniejsze. Jest to wiersz poleceń uruchomiony w ramach Windows Preinstallation Enviroment, który de facto jest okrojonym zwykłym Windowsem uruchomionym z płyty instalacyjnej. Należy zwrócić uwagę na znaczący postęp w stosunku do konsoli odzyskiwania z systemów XP i niższych, która w obsłudze była niesamowicie toporna i mało użyteczna. Wiersz poleceń z płyty instalacyjnej daje nam znacznie większe możliwości niż stara konsola, oprócz dostępu do plików na dysku również możliwość uruchamiania aplikacji graficznych np. regedit.
A przy użyciu regedit możliwe jest załadowanie i wyedytowanie plików rejestru dowolnego Windowsa, co umożliwia wykonanie wszelkich napraw związanych z konfiguracją zapisaną właśnie w rejestrze. Po wpisaniu w wierszu poleceń regedit uruchomi się edytor z załadowanym rejestrem Windows Preinstallation Enviroment. Należy wybrać gałąź, którą chcemy załadować np. HKLM, wybrać opcję Load hive i wskazać odpowiedni plik z katalogu system32\config instalacji Windows, którą naprawiamy. Dla HKLM będzie to plik SYSTEM. Następnie podajemy dowolną nazwę, pod którą nastąpi “zamontowanie” ładowanego rejestru, na obrazku poniżej wpisałem WINXP_HKLM. Następnie odczytujemy z klucza select, który z ControlSet jest aktywny, zazwyczaj będzie to pierwszy. Wchodząc do gałęzi services uzyskujemy możliwość edycji usług i sterowników - wartość 4 klucza Start oznacza wyłączenie sterownika lub usługi, 2 oznacza start automatyczny.
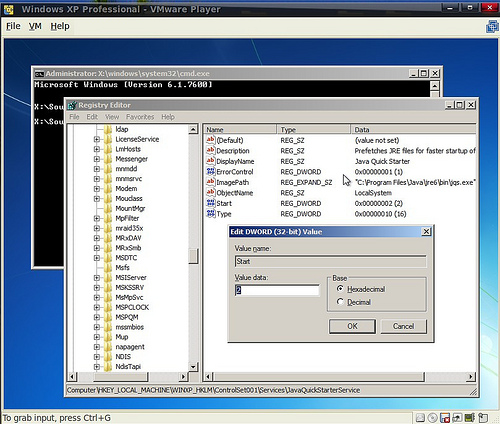
Powyższy zrzut ekranu wykonałem edytując rejestr systemu XP przy użyciu płyty instalacyjnej systemu w wersji 7. Warto znać taki właśnie sposób naprawy, ponieważ awarie w znakomitej większości powodowane są błędami w sterownikach trybu jądra, dzięki opisanej sztuczce możliwe jest wyłączenie takiego problematycznego sterownika.
Wpis ten jest rozwinięciem pomysłów, które opisałem w ubiegłym roku tutaj. Wraz z dynamicznym rozwojem zjawisk zachodzących w obrębie szeroko rozumianego Web 2.0, stwierdziłem, że konieczne jest wprowadzenie dodatkowych rozwiązań oraz wyrobienie nowych nawyków w stosunku do tego, co zostało opisane wcześniej.
Obawiam się Cross-site-scripting
O tym czym jest, jak wygląda i co powoduje XSS pokazywałem na przykładzie słynnych stron rzekomo “usuwających” funkcjonalność “Śledzika” z serwisu NK. Generalnie chodzi o to, że gdy jestem zalogowany na pewnej stronie internetowej, np. NK, albo FB w innych kartach przeglądarki zwykle oglądam też jeszcze inne strony. Może się zdarzyć tak, że gdzieś kliknę w pewien złośliwy link, który prowadzi do strony ze skryptem. Ten skrypt z kolei może wykonać bez mojej wiedzy i zgody pewną czynność wykorzystując to, że jestem właśnie zalogowany na swoim koncie. W opisywanym przeze mnie przykładzie było to automatyczne wklejenie komunikatu do “Śledzika”, który pokazywał się naszym znajomym. Innym tego typu przykładem jest strona “110 Hottest Women in The World”, która namawia do “polubienia” jej na FB, po czym bez naszej wiedzy i zgody wkleja się do strumienia aktualności uwidaczniając się wszystkim naszym znajomym. Odrębną kwestią jest konsekwentna nieufność wobec wszelkich stron, które namawiają nas do “polubienia” na FB albo sugerują ściągnięcie i uruchomienie jakiegoś pliku, po to, żeby coś ciekawego zobaczyć. Takie coś świadomy użytkownik natychmiast i bez zastanowienia ignoruje, ponieważ od razu widać, o co tak naprawdę chodzi. Na dzień dzisiejszy tego typu złośliwe sztuczki nie powodują większych szkód, ponieważ “jedynie” umieszczają pewne treści na naszej tablicy FB. Tym, co mnie martwi jednak, są: po pierwsze potężne możliwości rozprzestrzeniania się, po drugie możliwości ewoluowania tego typu technik i łączenia ich np. z lukami typu zero-day. Zauważmy, że jest bardzo prawdopodobne, że w tym przypadku sporo osób kliknie w złośliwy link. Wszak pojawił się on u naszego znajomego na tablicy, to już samo w sobie budzi zaufanie, ponadto skoro się tam pojawił, to znaczy, że ten znajomy uważa, że jest to coś fajnego, co warto zobaczyć. Jest to bardzo sprytny chwyt social-engineering, który skutecznie zwiększa grono potencjalnych ofiar. Niewykluczone, że w przyszłości pojawią się ataki, które tę sprytną sztuczkę będą wykorzystywać tylko do “rozmnażania się”, a ich sednem będzie exploit wykorzystujący nienaprawiony jeszcze błąd w przeglądarce powodujący zdalne wykonanie kodu. Innym możliwym scenariuszem jest “wstrzykiwanie” bez naszej wiedzy i zgody treści niecenzuralnych, żeby “uderzyć” w reputację użytkownika.
W związku z powyższym proponuję wdrożyć w prosty sposób zasadę izolacji i używać na co dzień przynajmniej dwóch przeglądarek internetowych jednocześnie. Jednej z nich używać jedynie do usług, w których zwykle jesteśmy cały czas zalogowani jak np. GMail czy FB, drugą natomiast do zwykłego przeglądania stron internetowych. Zgodnie z tym, co opisywałem w ubiegłym roku, oczywiście obie przeglądarki uruchamiam przez Sandboxie. Ponadto w tej przeznaczonej dla usług korzystam z dodatku NoScript, którym ograniczam wykonywanie skryptów JavaScript tylko do stron z usługami np. google.com czy facebook.com i żadnych innych. Myślę, że jest to skuteczny kompromis pomiędzy wygodą i w miarę przyzwoitym poziomem ochrony. Korzystanie w “przeglądarce do przeglądania” z NoScript mogłoby być uciążliwe, ponieważ JavaScript jest jednak fundamentem większości stron internetowych. Jeśli chodzi o konkrety - ja osobiście używam do przeglądania Firefoxa, natomiast dla usług wybrałem SeaMonkey (przeglądarkę, która w prostej linii jest kontynuacją Mozilla Suite). Eksperymentowałem z Google Chrome, jednakże jak dla mnie jest to przeglądarka o zbyt prymitywnym interfejsie i możliwościach konfiguracji. Co więcej, podczas działania w Sandboxie zawieszała się kilka razy dziennie, co zdyskwalifikowało ją kompletnie. Najchętniej korzystałbym z dwóch Firefoxów, jednakże jest to niemożliwe technicznie - proces Firefoxa może być tylko jeden w systemie. Fakt - mogę uruchomić go z konta innego użytkownika, ale wtedy nie byłby w Sandboxie, który działa tylko dla aktualnie zalogowanego użytkownika. Wybrałem więc starą, dobrą Mozillę, którą miło wspominam jeszcze z początku dekady, gdy w wersjach 1.x w tamtym czasie była o całe lata świetlne w rozwoju przed konkurencją (co ciekawe, wydaje mi się, że SeaMonkey jest szybszy od Firefoxa)
Wiem, jak na implementację zasady security by isolation to trochę za mało. Co prawda Sandboxie skutecznie utrudnia wprowadzenie jakiegokolwiek złośliwego oprogramowania do mojego komputera, to jednak nie chroni przed wszystkimi scenariuszami. Można sobie wyobrazić rozwiązanie, które wyexploituje mi przeglądarkę, odczyta pewne dane z mojego dysku i gdzieś je od razu prześle. Przed czymś takim Sandboxie nie chroni. Najlepiej byłoby używać różnych wirtualnych maszyn do różnych czynności, tak jak proponuje Joanna Rutkowska. Wówczas wyexploitowanie jednej z nich nie spowoduje żadnych strat, co więcej, nie będzie trwałe, bo maszyny po użyciu przywraca się do stanu zapamiętanego migawką. Niestety wadą takiego rozwiązania jest to, że byłoby to zbyt powolne i kłopotliwe przy użyciu komputera o przeciętnych parametrach. Teoretycznie idealnym rozwiązaniem byłoby stosowanie systemu operacyjnego Qubes OS tworzonego przez firmę Joanny Rutkowskiej - Invisible Things Lab. System ten zbudowany jest na hypervisorze Xen i automatyzuje tworzenie i uruchamianie maszyn wirtualnych, tak jakby były zwykłymi programami. Jednakże jak na razie jest to rozwiązanie we wczesnej wersji rozwojowej i nie nadaje się do pracy jako system operacyjny ogólnego przeznaczenia.
Unikam ciasteczek
Dosyć poważnym zagadnieniem jest skala zbierania i przetwarzania informacji o użytkownikach przez takie firmy jak Google. Ciasteczko odpowiada za utrzymanie sesji przeglądarki internetowej ze stroną, umożliwia zauważenie przez serwer, że konkretne wejścia na stronę (i inne działania w ramach strony) wykonywane są przez tego samego użytkownika - posiadającego zapamiętane w przeglądarce ciasteczko. Google na przykład może analizować wpisywane przeze mnie słowa do wyszukiwarki i przyporządkować je do mojego konta jeśli jestem podczas wyszukiwania zalogowany. Tutaj dodatkowym plusem dwóch przeglądarek jest oddzielenie zalogowania na koncie Google (przeglądarka dla usług) od zwykłego wyszukiwania (przeglądarka “do przeglądania”). Fakt, cały czas jestem tym samym adresem IP. Jednakże współcześnie sam adres IP nie wystarczy do pełnego zidentyfikowania sesji użytkownika - wszak może to być ktoś zupełnie inny za moim NAT’em. Wracając do ciasteczek - ustawiłem swoje przeglądarki internetowe tak, aby kasowały ciasteczka po ich zamykaniu. Dzięki temu w pewnym stopniu utrudniam analizę danych na mój temat wprowadzając “szum” - każda odsłona powoduje utworzenie nowego ciasteczka, czyli teoretycznie chodzi o innego użytkownika. Gdzieś słyszałem, że jedno z ciasteczek ustawianych przez wyszukiwarkę Google ma okres ważności do 2020 roku. Możecie sobie, drodzy czytelnicy, wyobrazić komu i do czego potrzebne są analizy aktywności użytkownika w tak długim czasie? Usuwanie ciasteczek nie wpływa znacząco na obniżenie wygody, jedynie zmusza nas do zrezygnowania z opcji typu “zapamiętaj mnie” podczas logowania na stronach, której i tak nie powinno się używać.
W temacie ciasteczek warto wspomnieć również o innej ich kategorii, mianowicie o ciasteczkach wtyczki Flash. Pełnią one taką samą funkcję jak zwykłe ciasteczka, mają większe możliwości i bardzo niewiele osób o nich wie. Szczegółowy opis problemu jest na blogu Piotra Koniecznego. Warto więc wyłączyć również i te ciasteczka za pomocą opcji dostępnych po kliknięciu prawym przyciskiem myszki na dowolnej animacji Flash.
Unikanie ciasteczek jest ważnym aspektem prywatności przeglądania stron internetowych, ale jeżeli ktoś się bardzo postara to i tak może spróbować nas zidentyfikować. Przykładowo istnieją metody wyciągania wniosków z tego, jakimi wtyczkami i jakimi czcionkami nasza przeglądarka może “pochwalić się” serwerowi. Projekt Panopticlick pokazuje jak bardzo unikatowy jest zestaw możliwości naszej przeglądarki. Konfiguracja taka jak moja zdarza się raz na milion według tej strony, co trochę mnie martwi. Co ciekawe, według powyższej strony ta moja unikatowość “generowana” jest przez dość skromny zestaw wtyczek - najnowsze wersje środowiska Java, czy Adobe Flash. Czyżby rzeczywiście tak niewielu użytkowników dbało o aktualność swojego oprogramowania? Jeszcze inną “magiczną” sztuczką jest próba wnioskowania czegoś o historii przeglądanych stron korzystając z możliwości ustawienia różnego wyglądu dla elementów wcześniej odwiedzonych. Przykładem takiej techniki jest strona, za pomocą której można robić znajomym dowcipy: didyouwatchporn.com. Technicznie działa to w ten sposób, że można zdefiniować za pomocą CSS, żeby link do strony X zawierał obrazek w przypadku gdy X była odwiedzona (klasa :visited). Jeżeli serwer odnotuje pobranie obrazka, wyciągamy wniosek, że użytkownik odwiedził stronę X. Moim zdaniem jednak powyższe mechanizmy nie odgrywają dużej roli, ponieważ de facto są pewnym rodzajem heurystyk i nie dają gwarancji zidentyfikowania użytkownika. To trochę tak jakby np. próbować zidentyfikować kogoś na podstawie koloru i wyposażenia jego samochodu. Fakt, zestaw typu (marka, kolor, silnik turbodiesel, przyciemniane szyby, alufelgi) może być dość unikatowy, ale przecież na tej podstawie nie można mieć stuprocentowej pewności co do identyfikacji konkretnej osoby.
Adobe i “spółka” jest większym problemem niż się wydaje
Programy firmy Adobe - mam tu na myśli wtyczkę Flash oraz czytnik plików PDF Adobe Reader w ostatnim czasie są coraz częstszym obiektem ataków. Niemalże każda kolejna wersja Reader’a zawiera jakąś krytyczną poprawkę naprawiającą błąd, który mógł spowodować zainstalowanie złośliwego oprogramowania w naszym komputerze tylko w wyniku samego otwarcia pliku PDF. Podobnie jest z odtwarzaczem animacji Flash (analogicznie - samo wejście na stronę z animacją mogło wyrządzić nam krzywdę). Wielu nietechnicznym użytkownikom trudno jest uświadomić konieczność aktualizacji systemu operacyjnego czy przeglądarki, nie wspominając już o konieczności aktualizacji “dodatków” firmy Adobe, z czego mało kto sobie zdaje sprawę. A jest to tak samo ważne, ponieważ wiąże się z tymi samymi zagrożeniami. Adobe Reader jest programem wyjątkowo nieprzyjemnym, chociażby dlatego, że instaluje się dodatkowo w przeglądarce jako wtyczka powodująca automatyczne otwieranie pliku PDF w oknie przeglądarki bez pytania o zgodę. W związku z tym, jeżeli już używamy Adobe Readera polecam wyłączyć tę wtyczkę do przeglądarki, aby ręcznie pobierać plik PDF i ręcznie otwierać. Osobiście rozważam zrezygnowanie z Adobre Reader’a na rzecz np. Sumatra PDF albo Foxit. Tymczasem, jeżeli trzeba używać Adobe Readera - polecam uruchamiać go również przez Sandboxie. Powyższe zalecenia dot. konieczności aktualizacji dotyczą również innych “dodatków” do przeglądarki jak np. środowiska Java. Dbanie o używanie aktualnych wersji oprogramowania powinno w świadomości użytkowników komputerów stać się niezbędnym elementem “konserwacji” swojego komputera takim samym jak na przykład wymiana oleju w przypadku samochodu (tu chyba nikt nie ma wątpliwości, że jest to konieczne).
Do naprawdę wrażliwych operacji warto jednak mieć maszynę wirtualną
Do operacji bankowych używam właśnie Xubuntu uruchamianego w Oracle VirtualBox. Po każdym uruchomieniu przywracam dysk maszyny do wcześniej zapamiętanego stanu, dzięki temu przez cały czas mam taki sam, “czysty” system. Gdyby jakimś cudem w moim komputerze znalazło się oprogramowanie np. przechwytujące naciśnięcia klawiszy - to nie przechwyci ono tego, co się wpisuje wewnątrz maszyny wirtualnej. Sprawdzałem działanie mechanizmu Hooks w systemie Windows - faktycznie “haki” przechwytujące naciśnięcia klawiszy nie “wyłapują” tego, co się dzieje w maszynie wirtualnej. Jest to więc bardzo silne i skuteczne rozwiązanie praktycznie uniemożliwiające przedostanie się jakiegokolwiek złośliwego oprogramowania zarówno w kierunku mój system operacyjny -> maszyna wirtualna, jak również w odwrotnym kierunku, ponieważ zakładam, że tej maszyny używam tylko do łączenia się z witryną banku. W przyszłości zamierzam jeszcze wdrożyć pomysł Joanny Rutkowskiej i zmodyfikować wirtualną sieć, tak, aby ta konkretna maszyna mogła łączyć się tylko z jednym adresem IP (zastanawiam się właśnie jak ona to zrobiła, podejrzewam, że w VMware efekt ten można uzyskać za pomocą narzędzia konfiguracji sieci dostępnego przez skrót Manage Virtual Networks)

PS. Platformie blogowej blox.pl gratuluję ograniczenia długości wpisu do 16KB. Ostatnią sekcję tego tekstu musiałem wkleić jako obrazek…
Na szczęście to nie ja dostąpiłem wątpliwego zaszczytu bycia tym użytkownikiem, tylko kolega (pozdr. dla Vincenta i dzięki za info). Poniższy obrazek to podobno tylko wierzchołek góry lodowej jeśli chodzi o kłopoty z programami do obsługi urządzeń tej firmy.
Gdy pracuję w systemie Linux i korzystam z mojego ulubionego klienta Bittorrent - Azureusa, często zachodzi potrzeba potraktowania tego programu poleceniami renice i ionice, żeby zwiększyć responsywność systemu, która mogła ucierpieć przez działanie złożonej Jav’owej aplikacji. Warto było w tym celu napisać sobie prosty skrypt. Pojawił się tutaj problem pobrania PID’u procesu na podstawie jego nazwy. Nie zagłębiając się specjalnie w naturę problemu (co okazało się błędem - o tym za chwilę) stworzyłem własne rozwiązanie tego problemu w ten sposób:
ps ax | grep "java.*Azureus" | awk {$0 = gensub(/legacy/blog/^ +/,"", "g", $0); print $1; exit}'
Dla zainteresowanych krótkie wytłumaczenie działania tej komendy:
ps ax - wyświetla listę wszystkich procesów użytkownika, również tych, które nie posiadają konsoli. Na początku każdego wiersza, tuż po spacji, jest szukany przeze mnie PID. Gdzieś pod koniec jest “command line” którym uruchomiono proces.
Odnajduję wiersz z procesem Jav’y, szukając słowa “java”, następnie dowolnej liczby dowolnych znaków, następnie słowa “Azureus”. Wzorzec ten “łapie” wiersz z procesem, którego szukam.
Następnie trzeba się jakoś pozbyć tej nieszczęsnej spacji na początku. Niestety prostym poleceniem cut nie dało rady, więc sięgnąłem po potężny AWK, który nadaje się idealnie, ponieważ przetwarza wierszami i od razu dzieli wiersz na rekordy. W “miniprogramie” AWK usuwam spację z początku wiersza “łapiąc” ją wyrażeniem regularnym “/^ +/” i usuwając. Następnie wypisuję pierwszy rekord wiersza, czyli szukany PID.
Jak widać powyższe rozwiązanie wbrew pozorom wykorzystuje sporo różnych pomysłów i w gruncie rzeczy nie wygląda na najprostsze. W tym momencie dochodzę do refleksji, która jest przedmiotem tego wpisu: otóż ktoś już wcześniej zauważył, że w życiu często zachodzi potrzeba znalezienia PID’u procesu po jego nazwie i wymyślono do tego oddzielne polecenie:
pgrep -f Azureus
Efekt jego działania jest dokładnie taki sam jak polecenia, które ułożyłem wcześniej. Wniosek z tego jest taki, że jeżeli zabieramy się za tworzenie własnego rozwiązania jakiegokolwiek problemu informatycznego (a może wcale nie tylko informatycznego), warto sprawdzić najpierw czy w danej chwili już nie dysponujemy narzędziami, którymi możemy ten problem rozwiązać natychmiast. Myślę, że przykładów podobnych, niezwykle użytecznych i mało znanych poleceń oraz funkcjonalności powłoki systemu Linux jest więcej, chociażby takie jak: watch, stat, column, reset czy mechanizmy zwane “event designator” albo “brace expansion”.
PS. Dla formalności dodam jeszcze, że podany wyżej “miniprogram” AWK też jest nadmiernie skomplikowany, bo okazuje się, że gensub nie jest potrzebny, samo "print $1" wystarczy :)
Zaintrygowało mnie eleganckie zapewnienie na stronie logowania czołowego niegdyś, polskiego serwisu społecznościowego: “Logujesz się bezpiecznie przez SSL”. Serwisy internetowe często stosują technikę polegającą na szyfrowaniu jedynie strony z formularzem do logowania, a przechodząc do właściwych stron serwisu zmieniają połączenie na zwykłe http (skoro nie dajemy rady ochronić wszystkich twoich danych, to zabezpieczymy przynajmniej twoje hasło). Myślałem, że tak jest i tym razem, chociaż nie widziałem typowego w takich sytuacjach mignięcia paska adresu na żółto w krótkiej chwili, gdy połączenie jest szyfrowane.
Aby się upewnić włączyłem w mojej przeglądarce ostrzeżenie przy otwieraniu zaszyfrowanej strony: w Mozilla Firefox - opcje -> bezpieczeństwo -> ostrzeżenia -> ustawienia: wyświetlaj ostrzeżenie przy “otwieraniu zaszyfrowanej strony”. Podczas logowania do serwisu, ostrzeżenie wbrew obietnicom napisanym pogrubioną czcionką nie pojawia się, co oznacza tyle, że połączenie wcale bezpieczne nie jest.
Jakie to ma praktyczne konsekwencje? Szczerze mówiąc niewielkie o ile nie łączymy się z Internetem np. poprzez ogólnodostępny, darmowy “hot-spot” gdzie istnieje realna szansa podsłuchania całego ruchu w sieci w bardzo prosty sposób. Głównym celem szyfrowania połączenia ze stroną internetową jest zapewnienie, że jeżeli ktoś, kto “po drodze” od naszej przeglądarki do serwera ze stroną internetową uzyska dostęp do medium transmisyjnego, to jednak nie uzyska dostępu do danych. W przypadku niezabezpieczonych sieci bezprzewodowych niebezpieczeństwo jest duże, dlatego, że taki podsłuch jest właśnie trywialnie prosty - wszak nośnikiem jest eter. W przypadku połączenia kablowego (pomijając infrastrukturę sieci lokalnej w szkole/uczelni/pracy, która może być tak zbudowana, że podsłuch jest możliwy w jej obrębie) niebezpieczeństwo przechwycenia niezaszyfrowanych danych na drodze od naszego usługodawcy internetowego do serwera docelowego jest raczej średnie, ponieważ byłoby po prostu dość skomplikowane technicznie (ale jak najbardziej możliwe).
Jakie to ma inne konsekwencje? Tylko wizerunkowe. Nie podoba mi się to, że serwis mnie oszukuje już na powitanie.
U konkurencji jest lepiej, bo:
NK zapewnia oddzielny link do logowania przez SSL widoczny na stronie głównej
FB zapewnia szyfrowanie SSL, gdy w pasku adresu ręcznie podmienimy http na https. Jednakże na stronie głównej nie informuje o takiej możliwości. Co ciekawe, szyfrowanie jest domyślne podczas edytowania danych swojego konta, co trochę dziwi wobec nie szyfrowania samego logowania do serwisu.
Deklarowałem się, że nie będę podawać na blogu news’ów, ale ta informacja jest dosyć istotna dla osób korzystających z wirtualizacji, a nie została zauważona w żadnym z serwisów, które śledzę.
Od ok. 2 lat używam i polecam znajomym program Sun Virtualbox. Jest to narzędzie darmowe posiadające wszystkie niezbędne funkcje. VMware Player do wersji 3 był programem pozwalającym jedynie na uruchamianie istniejących maszyn, a nie ich tworzenie. Natomiast od wersji 3 wprowadzono również możliwość tworzenia nowych maszyn. Oznacza to, że do grupy darmowych, w pełni funkcjonalnych programów można zaliczyć również VMware Player’a. Różnicą w stosunku do płatnego Workstation jest brak możliwości tworzenia migawek (swoją drogą pamiętam, że w Workstation kiedyś dawno temu też tego nie było) oraz brak jakichś mało użytecznych dla skromnego użytkownika funkcji do pracy w grupie.
Testowałem VMware Player na razie tylko w wersji dla systemu Linux i w moim odczuciu działa znacznie wydajniej od Sun Virtualbox’a. Przykładowo odtwarzanie filmów z Youtube działa (system gościa to Windows) całkowicie płynnie, czego o maszynie w Virtualbox powiedzieć nie można. Zapewne dzięki wsparciu dla przyspieszenia sprzętowego w wyświetlaniu grafiki.
{kind=link}